Perceptual Quality Assessment and Enhancement of Visual Media using Generative Priors.
SHRESHTH SAINI
PhD Student, The University of Texas at Austin
PhD Dissertation Defense
April 2026
Candidate & Committee Members

Shreshth Saini
Candidate
UT-Austin

Prof. Alan C. Bovik (Advisor)
Chair/Member
UT-Austin

Prof. Joydeep Ghosh
Member — UT-Austin

Prof. Diana Marculescu
Member — UT-Austin

Dr. Yan Ye
Member — Alibaba Group US

Dr. Balu Adsumilli
Member — Google Inc.
Dissertation Roadmap
Part I: Perceptual Quality Assessment
Beyond8Bits & BrightRate Review
HDR-UGC datasets & quality models (WACV '24, '26 + ICIP '24)
LGDM: Latent Guidance in Diffusion Models Review
Zero-shot IQA via generative priors (ICML '25)
HDR-Q: MLLM for HDR VQA CVPR '26
First multimodal LLM for HDR quality — HAPO framework
Part II: Generative Enhancement
Rectified-CFG++ NeurIPS '25
On-manifold guidance for rectified flow models
LumaFlux: Inverse Tone Mapping
Physically & perceptually guided SDR→HDR via DiT
Future Directions
Unified perception-generation framework
Unifying theme: Generative models as both evaluators and enhancers of visual quality
Progress Review Recap
Beyond8Bits & LGDM
Establishing HDR-UGC benchmarks and leveraging generative priors for perceptual quality
Review Beyond8Bits & BrightRate
The largest HDR-UGC video quality dataset & first HDR-aware blind VQA model
BrightRate: Multi-Stream VQA
- HDR features via expansive non-linearity on extreme luminance
- UGC features (CONTRIQUE) + CLIP semantic features
- Temporal difference module for flicker/quality fluctuations
- SROCC 0.889 vs. prior SOTA 0.853
4-Stage Pipeline
Video Sourcing (Vimeo+Users) → Bitrate Ladder Encoding → AMT Study (35 ratings/video) → SUREAL MOS Aggregation
HDR vs SDR gap, Beyond8Bits diversity, and HDR-Q improvements over baselines
Review LGDM: Latent Guidance for Quality Assessment
Zero-shot NR-IQA by exploiting generative priors — no task-specific training
Core Insight
Pretrained diffusion models encode a perceptual manifold. PMG steers sampling toward perceptually consistent regions — quality assessment without IQA labels.
Key Innovation: Diffusion Hyperfeatures
- Multi-timestep, multi-layer features from U-Net
- Theoretically grounded guidance on tangent spaces
- Works with off-the-shelf SD v1.5 — no fine-tuning
PMG: guide denoising toward perceptually consistent manifold regions
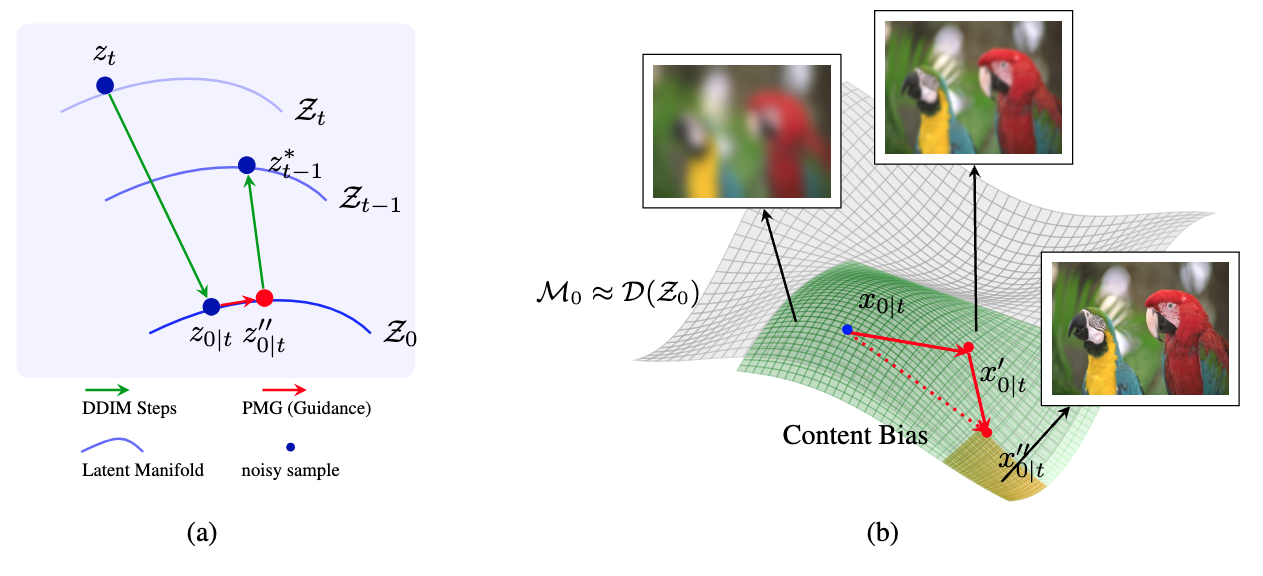
Perceptual Manifold Guidance — on-manifold quality-aware sampling
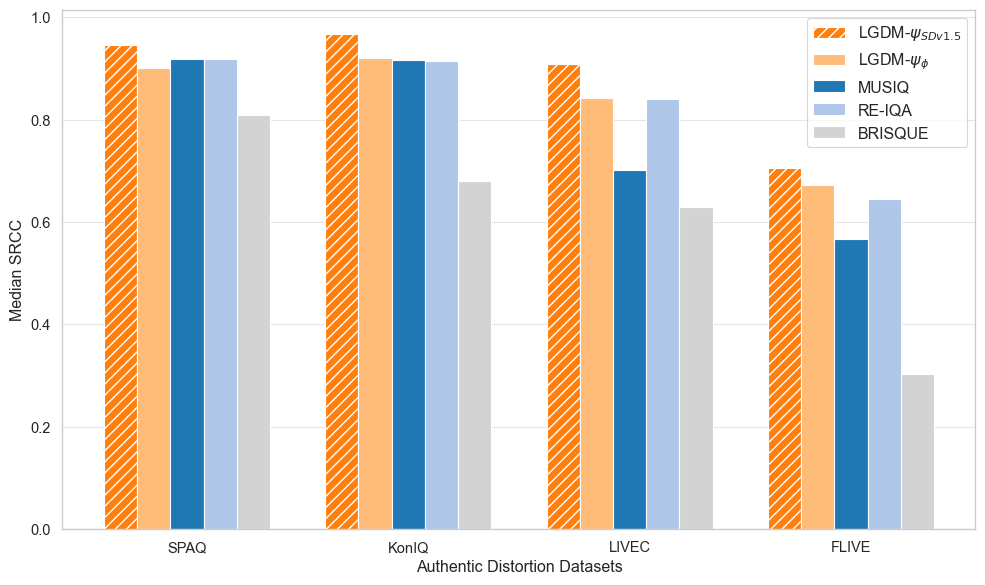
LGDM achieves SOTA median SRCC across authentic distortion benchmarks
Dissertation: Five Novel Contributions
Each project introduces new methods, datasets, or frameworks — together they form a complete pipeline from perception to generation for HDR visual media.
HDR Data
Gen. Priors
MLLM + RL
SDR→HDR
Flow Guidance
Unifying theme: Generative models as both evaluators and enhancers of visual quality
Part I: Perceptual Quality Assessment
HDR-Q: MLLM for HDR VQA
First multimodal LLM for HDR video quality assessment with HDR-Aware Policy Optimization
CVPR 2026
Can AI see and reason about
HDR video quality?
Today's answer: No. Every existing model was built for the 8-bit SDR world.
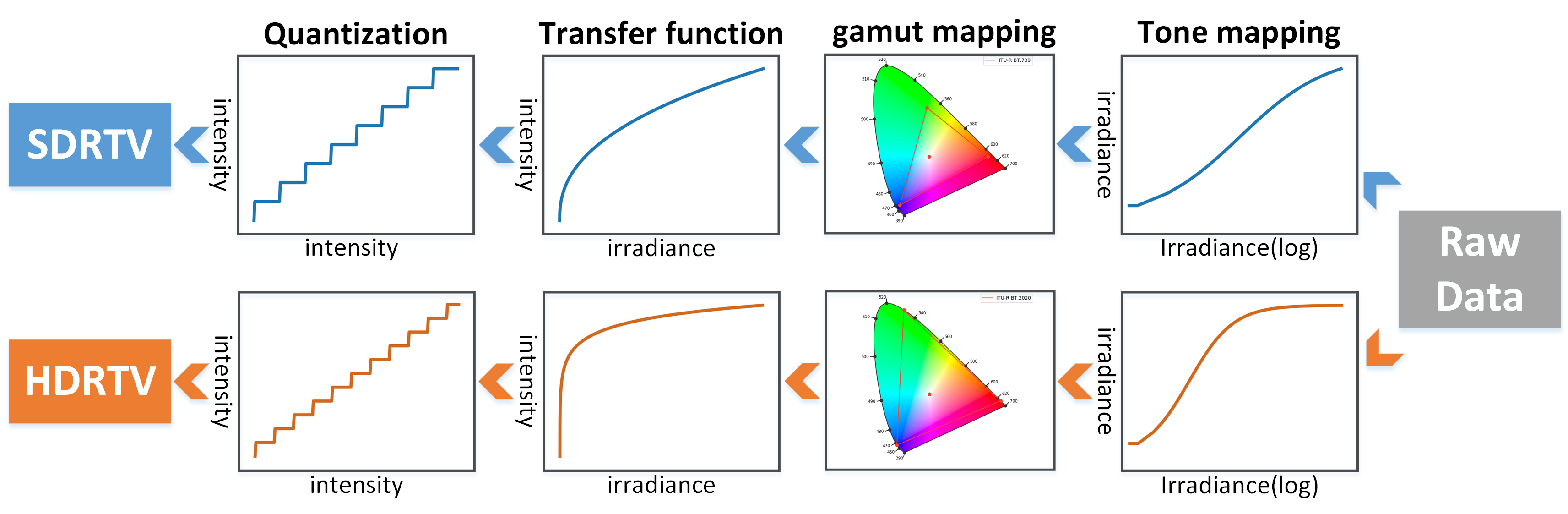
HDR Is Not "Better SDR" — It's a Different Signal Space
Every modern phone captures 10-bit HDR by default.
YouTube, Instagram, TikTok — billions of daily HDR uploads. HDR10 supports 10-bit depth, BT.2020 wide color gamut, PQ perceptual quantizer. Peak luminance ≥1000 nits vs SDR ~100 nits.
New perceptual phenomena SDR models cannot see:
Highlight clipping · Near-black banding · Color blooming · PQ quantization artifacts · Exposure flicker · Wide-gamut chroma shifts
Core argument:
Standard vision encoders (SigLIP, CLIP) process images in 8-bit sRGB. They are structurally blind to HDR-specific distortions. Not a training gap — a representation gap.

HDR preserves luminance and color detail that SDR collapses
Where Current Methods Break
No existing method combines HDR-aware perception with quality reasoning
| Method Family | HDR Input | Percept. Ground. | Reasoning | Cont. MOS | Interp. | SROCC |
|---|---|---|---|---|---|---|
| Classical (BRISQUE, VMAF) | ✗ | ✗ | ✗ | ✓ | ✗ | 0.41 |
| Deep VQA (FastVQA, DOVER) | ✗ | ~ | ✗ | ✓ | ✗ | 0.51 |
| HDR-Specific (HIDRO-VQA) | ✓ | ✓ | ✗ | ✓ | ✗ | 0.85 |
| MLLM-VQA (Q-Insight, DeQA) | ✗ | ✗ | ✓ | ~ | ✓ | 0.52 |
| HDR-Q (Ours) | ✓ | ✓ | ✓ | ✓ | ✓ | 0.92 |
The gap HDR-Q fills:
HDR-aware visual perception + continuous quality prediction + interpretable chain-of-thought reasoning. No prior method has all three.
Three Fundamental Obstacles
Each requires a dedicated solution — together they define the HDR-Q architecture
O1
SDR-pretrained
vision encoders
Blind to 10-bit PQ
O2
Continuous MOS
from token space
Bridging autoregressive & regression
O3
Modality
neglect
GRPO ignores HDR tokens
Evidence: GRPO with HDR input → 0.875 SROCC. SDR-only → 0.891. Adding HDR made it worse.
Beyond8Bits: The Foundation
First large-scale HDR-UGC quality dataset — the training ground for HDR-Q
Format: 10-bit HEVC, PQ transfer, BT.2020 · 360p–1080p · 0.2–5 Mbps bitrate ladder
Sources: 2,253 crowdsourced (diverse UGC) + 4,608 Vimeo CC (nature, outdoor, low-light)
Quality control: HDR10 display verification · Qualification quiz · Golden set (SROCC 0.85) · SUREAL MOS aggregation · Inter-subject SROCC 0.90
Dataset diversity, HDR vs SDR characteristics, and HDR-Q performance gains
HDR-Q: Architecture Overview
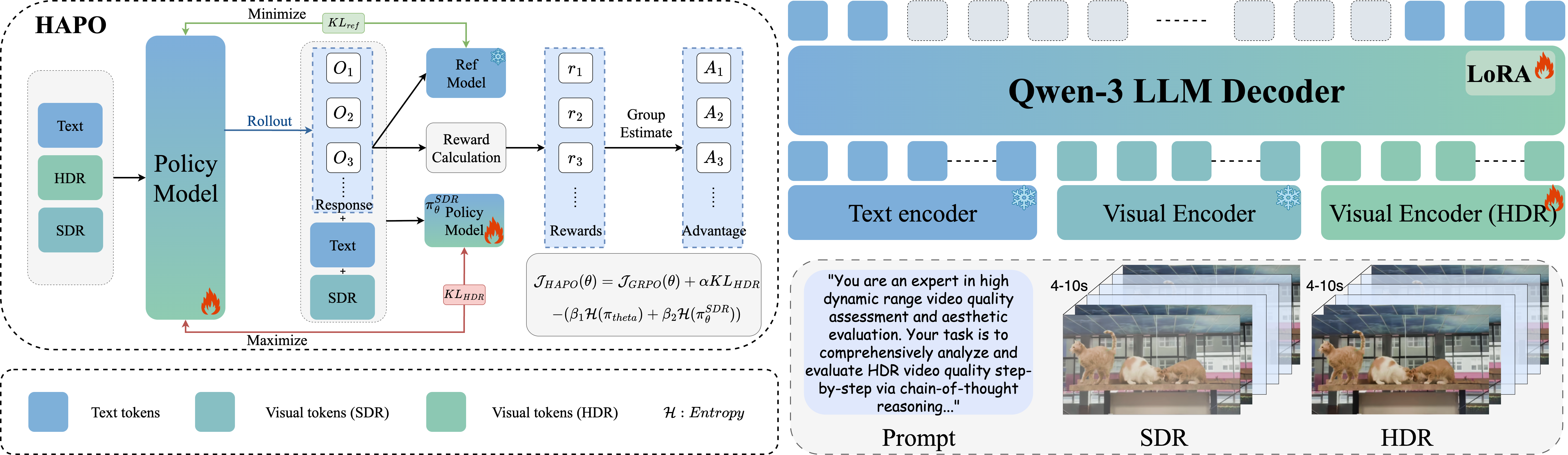
Solves O1: HDR-Aware Encoder
SigLIP-2 + dual-domain contrastive learning. Native 10-bit PQ. Dual HDR + SDR pathways.
Solves O3: HAPO Training
Contrastive KL + dual entropy + entropy-weighted advantage. Forces HDR modality attention.
Solves O2: Structured Output
Ovis2.5 (9B) + Rank-4 LoRA. <think> reasoning + <answer> MOS score. Gaussian reward σ=3.
HDR-Aware Vision Encoder
Contrastive HDR/SDR discrimination
Pull HDR close to caption, push SDR away
Full encoder loss
Semantic alignment + HDR discrimination
Design justifications
Why SigLIP-2? Strong semantic priors, multimodal-compatible.
Why contrastive? HDR info = what's in HDR but absent in SDR.
Why 10-bit PQ input? Tone-mapping destroys the signal we need.
Captions by Qwen2.5-VL-72B for quality-aware descriptions.
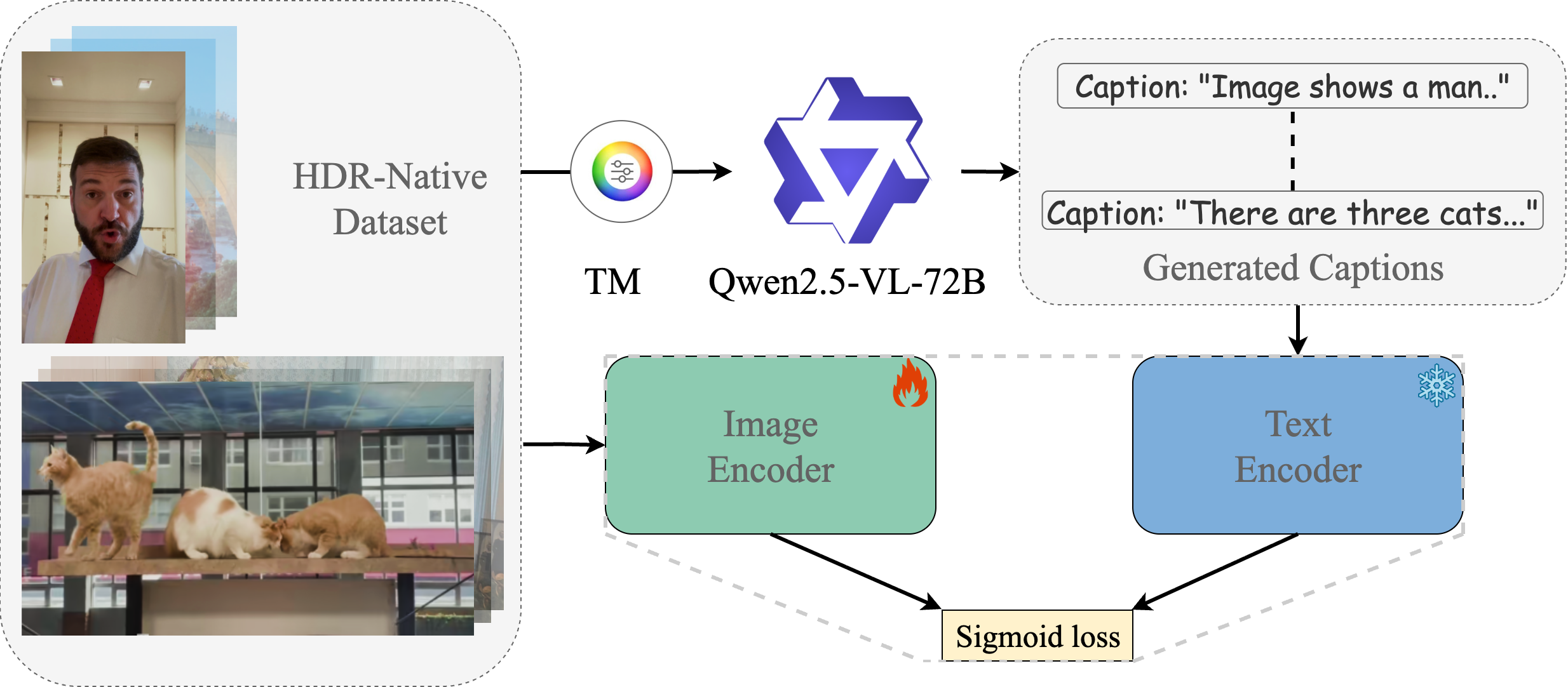
SigLIP-2 contrastive finetuning with matched HDR-SDR pairs and quality-aware captions
The Modality Neglect Problem
The most surprising finding — and the core motivation for HAPO
HDR-Q (SDR input only)
0.8914
Standard GRPO (HDR+SDR input)
0.8753
Adding HDR made it worse.
Why this happens:
- GRPO treats all tokens equally — no modality importance signal
- Autoregressive generation enables text-context shortcuts
- SDR features are familiar; HDR features are foreign → model ignores the foreign
- Result: higher input dimensionality, lower information utilization
HAPO fixes this: 0.9206 SROCC
By explicitly rewarding different outputs for HDR vs SDR inputs.
HAPO — Core Mechanism: HDR-SDR Contrastive KL
If the model ignores HDR → identical outputs for HDR & SDR → DKL ≈ 0. We maximize this divergence.
Maximized with coefficient γ = 0.5 in the HAPO objective
Mutual information between output and HDR content is lower-bounded. The policy is mathematically guaranteed to use HDR information.
The HAPO Objective
Entropy-weighted
advantage (HEW)
λHEW=0.3
Reference KL
stability
β=0.02
Contrastive KL
HDR grounding
γ=0.5
Dual entropy
anti-collapse
η₁=0.01, η₂=0.05
Training Pipeline & Reward Design
Stage 1: Modality Alignment
Full HAPO with γ=0.5. Curated Beyond8Bits subset with matched HDR-SDR pairs. Goal: teach model to attend to HDR-specific information. Both stages use RL — no SFT stage.
Stage 2: Quality Calibration
Full Beyond8Bits corpus. Score reward as primary signal, reduced γ. Goal: prediction accuracy while preserving HDR grounding from Stage 1.
Why two stages?
Modality alignment and quality calibration are competing objectives. Aggressive contrastive training degrades absolute accuracy; pure quality training enables modality neglect. Sequential prioritization resolves the tension.
Composite Reward
Rfmt: Binary — valid <think>/<answer> tags = 1
Rscore: Gaussian — exp(−(ŝ−s*)²/2σ²), σ=3. Smooth, differentiable.
Rself: Majority-vote consistency across K=8 completions.
Main Results: Beyond8Bits Benchmark
| Method | SROCC↑ | PLCC↑ | RMSE↓ |
|---|---|---|---|
| BRISQUE | 0.410 | 0.469 | 11.70 |
| CONTRIQUE | 0.625 | 0.605 | 15.02 |
| CONVIQT | 0.799 | 0.810 | 8.48 |
| HIDRO-VQA | 0.851 | 0.878 | 6.09 |
| Q-Insight (best MLLM) | 0.517 | 0.562 | 20.78 |
| HDR-Q (SDR only) | 0.891 | 0.890 | 7.42 |
| HDR-Q (Full) | 0.921 | 0.912 | 5.16 |
(zero-shot)
(zero-shot)
Zero-shot generalization without fine-tuning on target datasets
Qualitative: HDR-Q vs Baseline Reasoning

HDR-Q identifies true HDR artifacts (highlight preservation, banding, color fidelity). Ovis2.5 baseline hallucinates non-existent issues.
Ablation: Every Component Is Justified
| Variant | SROCC | RMSE | Tok. H |
|---|---|---|---|
| GRPO baseline | 0.81 | 10.73 | 0.20 |
| + HDR Encoder | 0.83 | 8.96 | 0.24 |
| HAPO w/o Contrastive KL | 0.86 | 7.10 | 0.29 |
| HAPO w/o HEW | 0.88 | 6.11 | 0.27 |
| HAPO w/o Dual Ent. | 0.91 | 5.82 | 0.26 |
| HDR-Q (Full) | 0.92 | 5.15 | 0.33 |
1. Contrastive KL — CRITICAL
0.92 → 0.86 without. Largest single drop. Prevents modality neglect.
2. HEW — Token-level credit assignment
0.92 → 0.88. Directs gradient to quality-relevant tokens.
3. HDR Encoder — Foundation
0.83 → 0.81. Essential for 10-bit PQ representation.
4. Dual Entropy — Stability
0.92 → 0.91. Prevents collapse, maintains exploration.
Token entropy: 0.20 → 0.33. Model becomes more uncertain at quality-critical decisions, not less. This is healthy.
Training Dynamics: HAPO vs GRPO
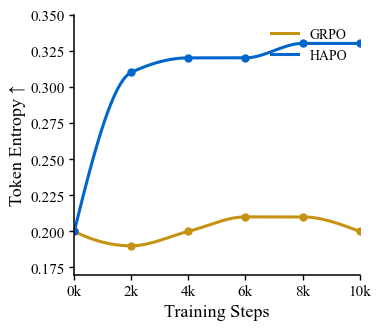
Token entropy during training — GRPO collapses, HAPO maintains healthy exploration
GRPO failure mode
Entropy drops → deterministic → ignores visual modality → text-context shortcuts
HAPO stabilization
Dual entropy maintains H ≈ 0.33 at quality-critical positions. Healthy exploration preserved.
Reasoning efficiency
CoT: 168 → 137 tokens (−18%). More concise, more focused. Boilerplate removed, quality observations retained.
What We Learn & Remaining Challenges
Key insights
- Modality neglect is the bottleneck, not encoder capacity. The contrastive KL mechanism is necessary and sufficient for HDR grounding.
- Token-level entropy is a diagnostic signal. Increasing entropy at decision points = better visual grounding. Collapsing entropy = text shortcuts.
- Two-stage RL outperforms SFT→RL. Both stages use RL, ensuring HDR grounding from initialization.
Remaining challenges
- Temporal reasoning is limited to T=8 frame sampling. Long-range temporal quality patterns may be missed.
- Extreme out-of-distribution content (e.g., synthetic HDR, gaming HDR) not well represented in training.
- Inference cost — MLLM inference is slower than lightweight VQA models. Not yet real-time.
Key Takeaways
First MLLM for HDR video quality. Prior MLLMs: 0.52 SROCC. HDR-Q: 0.92.
HAPO: principled solution to modality neglect. Three mechanisms, formal MI guarantee, all ablated.
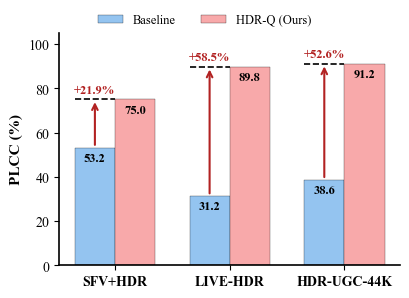
Strong zero-shot generalization. 0.908 LIVE-HDR, 0.725 SFV+HDR — no fine-tuning.
Perception-grounded reasoning. CoT references HDR-specific phenomena baseline models cannot articulate.
Next: HDR-Q as reward model for HDR generation & restoration → closing the perception-generation loop.
Part II: Generative Enhancement
LumaFlux: Inverse Tone Mapping
Physically & Perceptually Guided Diffusion Transformers for SDR→HDR
Can we teach a generative model
the physics of light?
SDR→HDR reconstruction is ill-posed. We need physical priors and perceptual guidance — not just more data.
What Happens When HDR Becomes SDR
Every step is lossy — inverting it is ill-posed
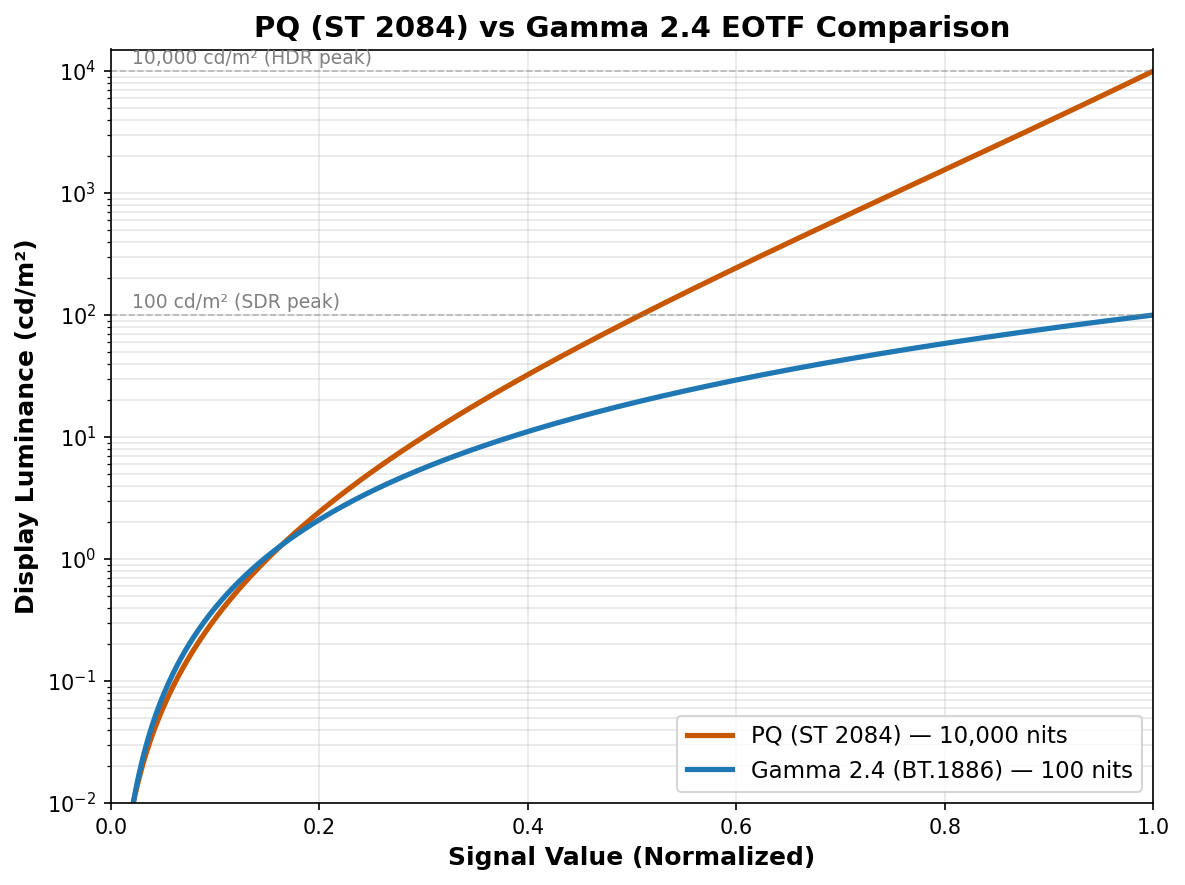
Luminance Compression
PQ: 0–10,000 cd/m². Gamma: 100 cd/m². SDR clips 99% of luminance.
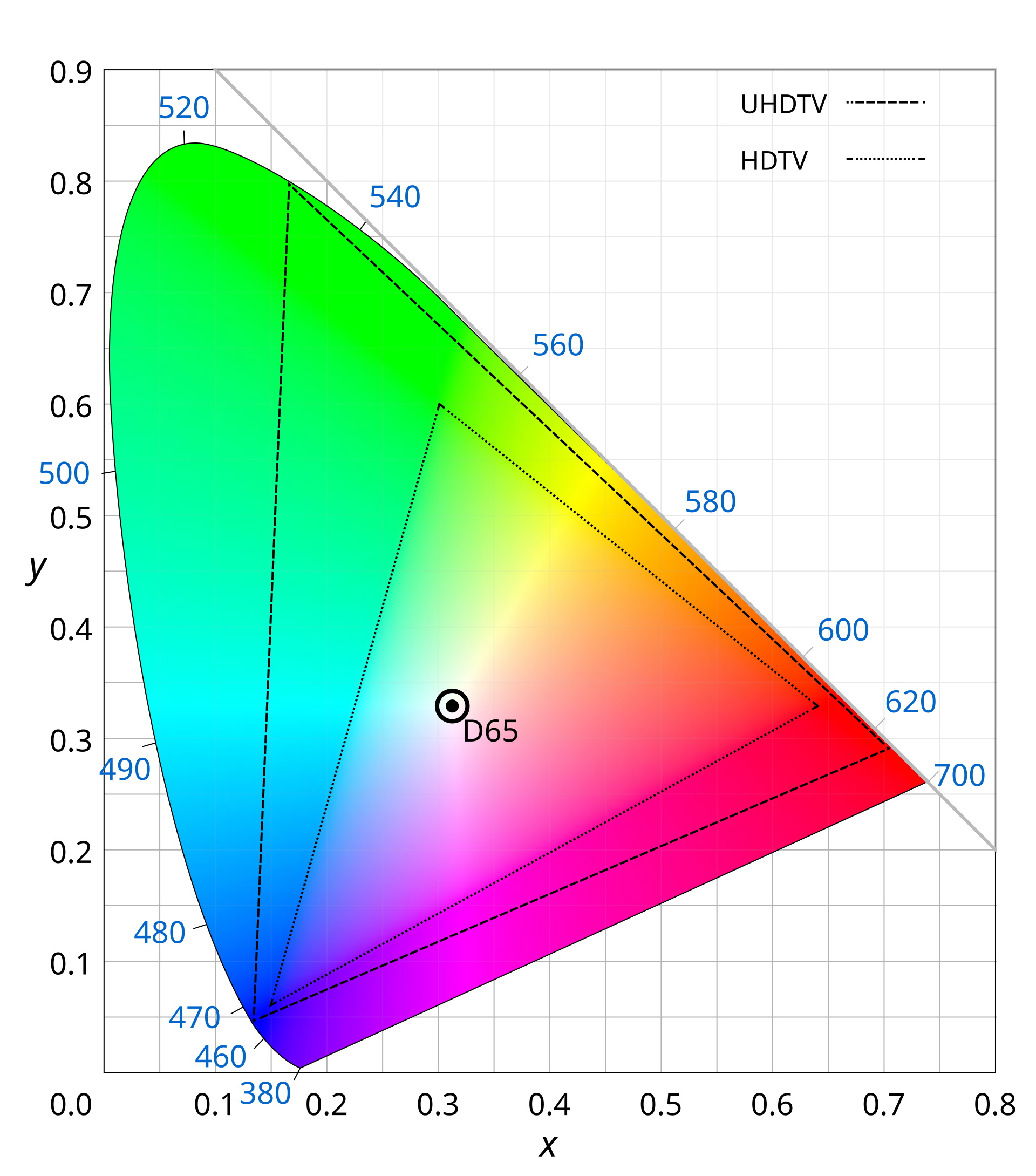
Color Gamut Compression
BT.2020: 75.8% of CIE. BT.709: 35.9%. Over half the color volume discarded.
What Gets Lost: 10-bit HDR vs 8-bit SDR (Beyond8Bits Dataset)
Split-view from our Beyond8Bits dataset — HDR (upper-left) vs SDR (lower-right) of the same frame
Refrigerator scene (top-left): SDR crushes shadow detail inside the fridge — metallic shelving and contents disappear to black. HDR reveals all internal structure.
Autumn lake (top-right): SDR desaturates the vivid fall foliage and loses the cloud detail in the sky. HDR preserves the full color volume and highlight gradations in the water reflection.
Crystal close-up (bottom): SDR clips the specular highlights on the gemstone to flat white. HDR preserves the translucent internal structure and surface reflections.
Real HDR Videos in Yxy Space: What SDR Clips
Computed from real 10-bit PQ BT.2020 videos (Beyond8Bits). Red prism = Rec.709 SDR volume (≤100 nits). Orange dots = pixels outside SDR — lost in tone mapping.
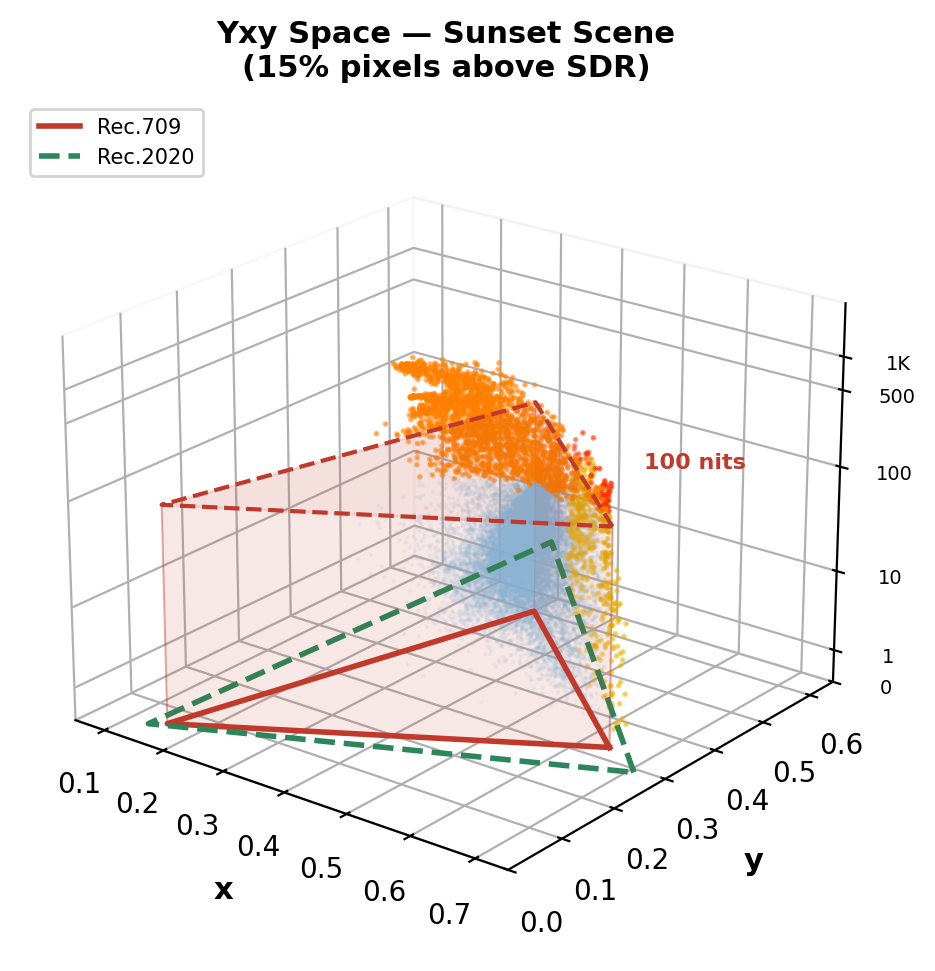
Sunset scene: 15% pixels above SDR ceiling. Sun flare + specular highlights on grass reach ~1,300 nits.
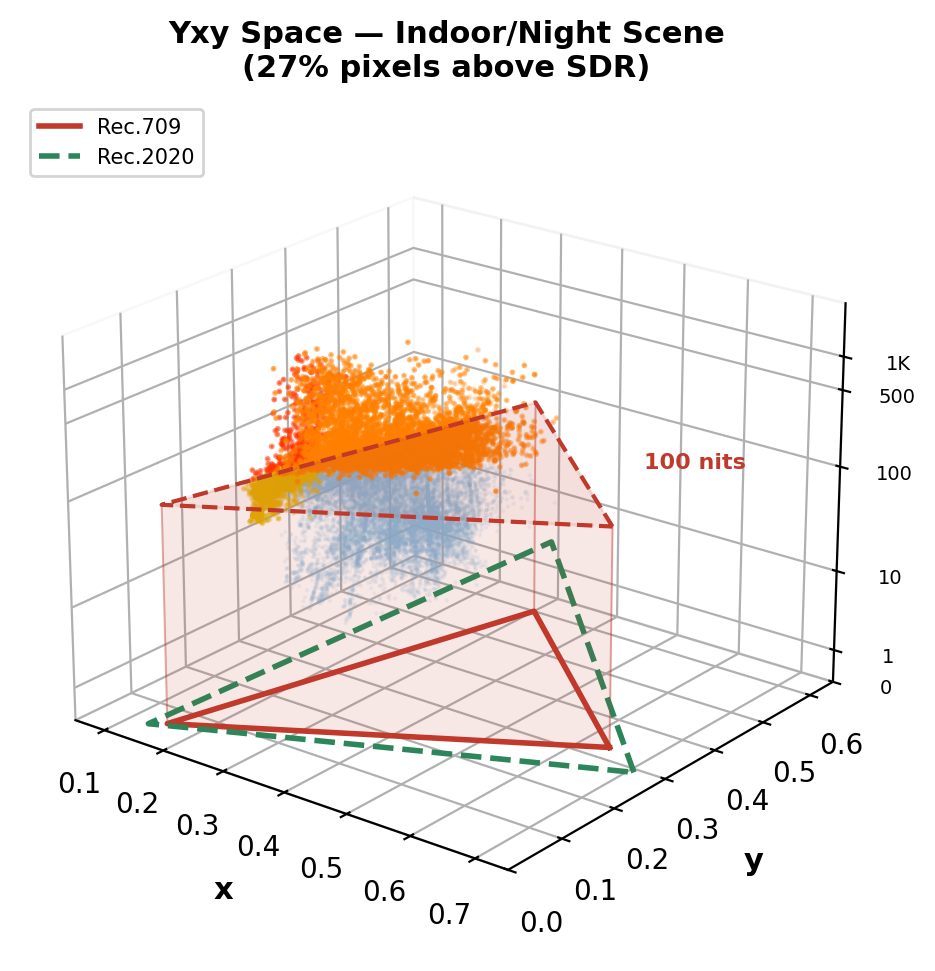
Indoor/night scene: 27% pixels above SDR ceiling. Bright artificial lights reach ~2,600 nits — massive clipping.
Key insight: 15–27% of HDR pixel information is permanently destroyed by SDR conversion — and the loss is concentrated in the most perceptually important regions: highlights, specular reflections, light sources, and wide-gamut colors. This is what ITM must reconstruct.
Why ITM Is Fundamentally Ill-Posed
Three irreversible losses make exact inversion impossible — any method must hallucinate missing information
1. Many-to-One Mapping
Forward tone mapping is surjective: multiple distinct HDR luminance values (e.g., 500, 2000, 8000 cd/m²) all map to the same clipped SDR code value (255). The inverse has infinite solutions — the mapping is non-invertible.
2. Color Gamut Loss
BT.2020 → BT.709 gamut mapping discards 53% of the color volume. Saturated greens, deep reds, and vivid cyans in the wide gamut are compressed into the sRGB triangle. The original chroma information cannot be recovered from the compressed representation.
3. Quantization Loss
10-bit PQ (1024 levels) → 8-bit gamma (256 levels) destroys fine gradations. In shadows, adjacent PQ code values are 4× further apart in 8-bit, causing visible banding/contouring. In highlights, the entire upper luminance range collapses to a few code values.
Any ITM method must hallucinate plausible HDR detail where SDR has none.
This requires content-aware generative priors — not fixed curves or local CNN features.
Prior ITM Methods: Three Generations of Architectures
From hand-crafted curves to CNNs to diffusion — each generation has fundamental limits
Gen 1: Classical Tone Curves
BT.2446, Reinhard, Huo et al. — Fixed parametric mapping from SDR→HDR using inverse tone curves. Content-blind: the same curve is applied to sunsets, interiors, and neon signs. Cannot recover scene-specific highlights or local contrast.
Gen 2: CNN-Based Learning
HDRTVNet++ (ICCV'21): 3-branch modulation net (global, local, condition). HDCFM (MM'22): Hierarchical feature modulation with dynamic context. HDRTVDM (CVPR'23): Dynamic context transformation. Deep SR-ITM (ICCV'19): Joint super-resolution + ITM.
Limitation: Local receptive fields → cannot model global illumination. Overfit to specific TMOs used in training data.
Gen 3: Diffusion-Based
LEDiff: Latent diffusion conditioned on SDR. PromptIR: Text-guided restoration. FlashVSR: Video super-resolution with diffusion prior.
Limitation: Hue shifts, over-saturated tones, hallucinated details. No physical grounding — the model has no concept of luminance or color space.
Gen 4: LumaFlux (Ours)
Physically & perceptually guided Diffusion Transformer. Frozen 12B Flux backbone + lightweight PGA/PCM modules. First to combine physical priors + perceptual guidance + DiT scale.
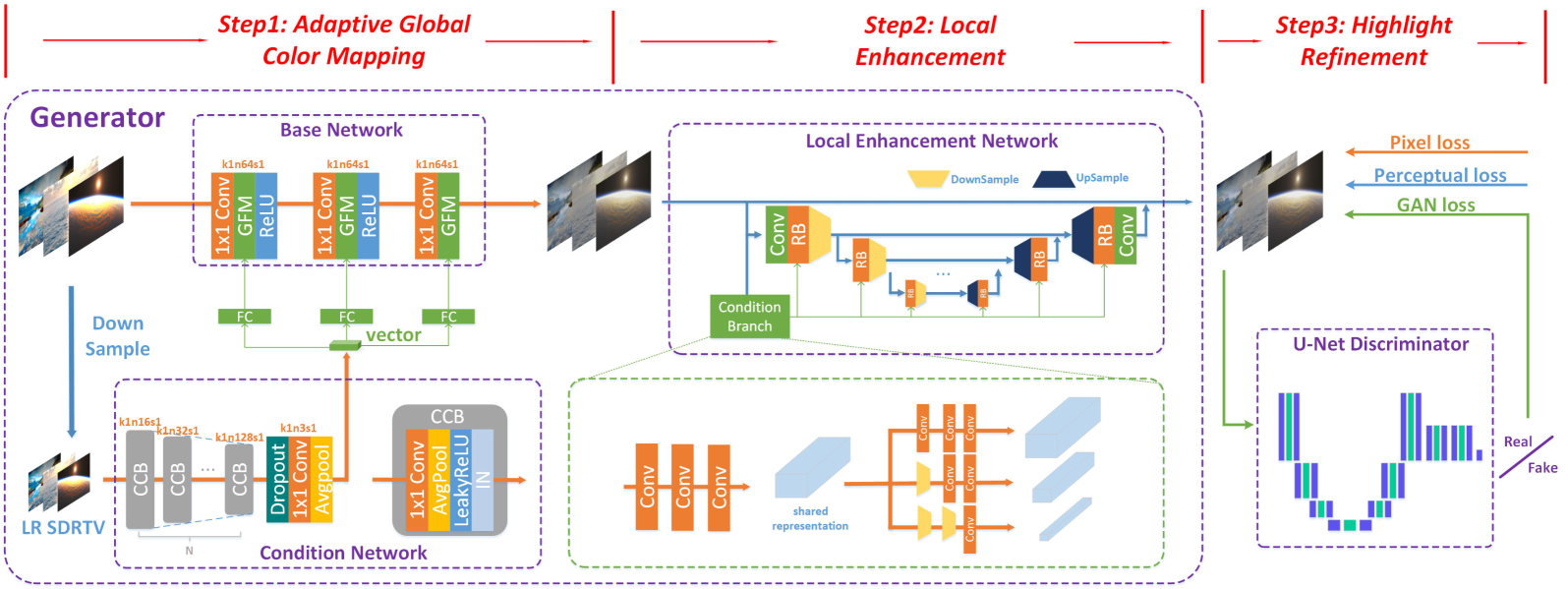
HDRTVNet++ — CNN, local ops only
LEDiff — latent fusion, no physical priors
Where Prior ITM Methods Break
Classical (Reinhard, BT.2446)
Fixed tone curves. Content-blind. Cannot recover scene-specific highlights.
CNN-based (HDRTVNet++, HDCFM, ICTCPNet)
Limited receptive field. Overfit to fixed tone operators. No global scene understanding.
Diffusion-based (LEDiff, PromptIR)
Color drift & hallucination. Require text prompts or retraining. No physical grounding.
What's missing?
No method uses physical priors (luminance, spectra).
No method uses perceptual priors (semantic understanding).
No method leverages modern DiTs (12B pretrained params).
| Method | Type | PSNR | Limitation |
|---|---|---|---|
| BT.2446 | Classical | — | Content-blind |
| HDRTVNet++ | CNN | 38.36 | Local receptive field |
| HDCFM | CNN | 38.42 | Fixed degradations |
| LEDiff | Diffusion | 36.52 | Color drift |
| PromptIR | Diffusion | 32.14 | Needs prompts |
| LumaFlux | DiT | 39.27 | Physics-guided |
Prior ITM Methods: Visual Failures
Visual comparison on real HDR dataset — from FastHDRNet (arXiv 2404.04483)

Desert sunset (top) + evening cityscape (bottom). Ground Truth vs 7 methods: Ada-3DLUT, HDRTVNet, JSI-GAN, CSRNet, HDRNet, HuoPhyEO, FastHDRNet.
Color shift & washout
Ada-3DLUT & HDRTVNet wash out the sun and lose sand gradients. HDRNet introduces severe blue color shift on the cityscape. HuoPhyEO produces unnatural yellow-green cast.
Halo & detail loss
JSI-GAN adds halo artifacts around the sun disc. CSRNet and JSI-GAN lose building detail and city lights in shadow regions. No method recovers both highlights and shadows.
The common pattern
CNN methods lack global context. Analytical methods lack content-awareness. No prior method uses physical priors or perceptual guidance — the exact gap LumaFlux fills.
Background Flow Matching in 4 Equations
The generation framework behind Flux and LumaFlux
1. Interpolation Path
data → noise, straight line
2. Target Velocity
Constant — network learns to predict this
3. Training Loss
Simple MSE: predicted vs true velocity
4. Inference: Solve ODE
t=1→0 via Euler. Deterministic, no noise.
Color: data x₀ · noise x₁ · interpolant xₜ · time t · network vθ
Background Rectified Flow: Straight Paths vs. Noisy Diffusion
Why LumaFlux uses rectified flow (Flux) instead of standard diffusion
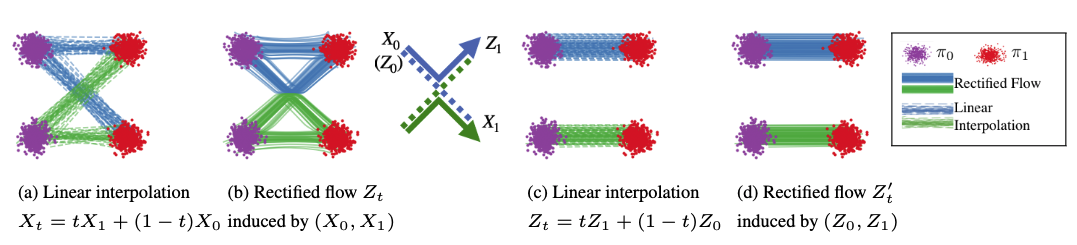
From Liu et al. (ICLR '23): (a) Linear interpolation has crossing paths. (b) Rectified flow straightens them via reflow. (c-d) After rectification, paths are straight ≈ optimal transport. Figure from official Rectified Flow repo.
Diffusion (SDE) — Curved, Noisy Paths
Stochastic noise at each step provides implicit error correction. Paths curve and cross. Requires 50+ steps. Models: DDPM, Stable Diffusion 1.5/2.
Rectified Flow (ODE) — Straight, Fast Paths
Deterministic ODE. Paths straightened via reflow ≈ optimal transport. Only 25-40 steps. Consistent outputs. Models: Flux (12B), SD3, SD3.5. LumaFlux builds on Flux.
Why this matters for ITM: Rectified flow gives us deterministic, consistent HDR outputs (no stochastic variation between runs) and fast inference (~8s/frame). The 12B Flux backbone provides rich visual priors from billions of training images — we just need to steer them with physics.
Background Flux MM-DiT & Why Standard LoRA Isn't Enough
Flux Architecture
12B-param MM-DiT. Visual + text tokens processed jointly via self-attention. Timestep conditioning via adaLN-Zero. Rectified flow ODE, 40 steps.
Standard LoRA
Rank r=8. Only 0.07% of parameters. Efficient but static.
Why vanilla LoRA fails for ITM
Same adaptation for all inputs, timesteps, layers.
No physics: blind to PQ curves, luminance, spectra.
No perception: can't enforce color constancy.
Result: 33.42 dB PSNR (baseline).
LumaFlux: From LoRA to Luma-MMDiT
Three extensions that make LoRA input-dependent, physically-grounded, and timestep-adaptive:
PGA — Physical gating on value projection
PCM — Perceptual FiLM on hidden states
RQS — Monotone spline tone-field decoder
TLAM — 6 scalars per (timestep, layer)
33.42 → 39.27 dB PSNR (+5.85 dB)
Architecture Evolution: CNN → MMDiT → Luma-MMDiT
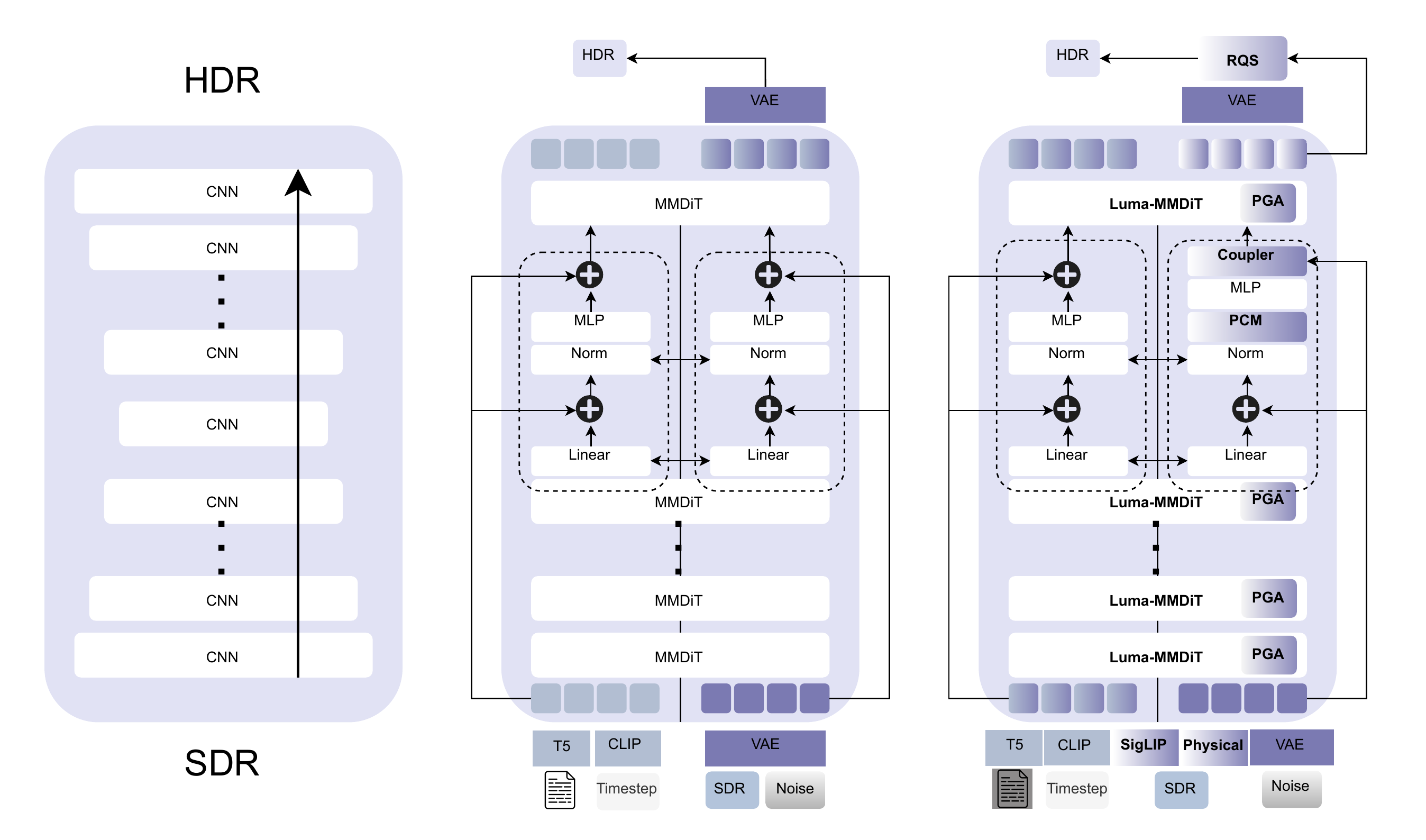
Left: CNN stack (local receptive field). Center: Standard Flux MMDiT (global attention but no physical priors). Right: LumaFlux (PGA + PCM + Coupler + RQS).
CNN: Local, no physical priors, no global context
MMDiT: Global attention, 12B priors, but static LoRA, no physics
Luma-MMDiT: + SigLIP + Physical features + spectral gating + RQS
LumaFlux: Full Pipeline
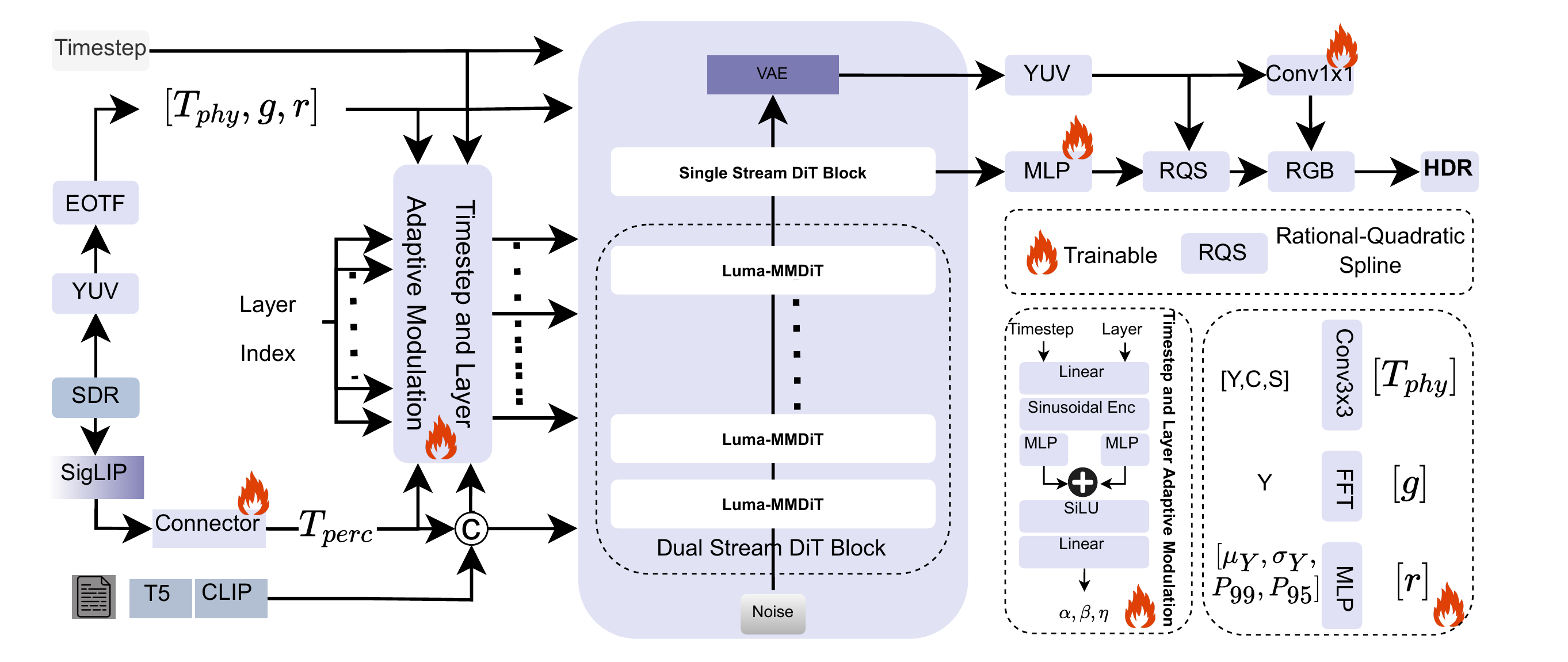
PGA
Luminance + gradient + saturation + FFT → gated LoRA on WV
PCM
Frozen SigLIP → cross-attn → FiLM: γ⊙LN(h)+ζ
TLAM
Ψ(t,ℓ) → 6 scalars controlling all modules per step/layer
RQS
K=8 monotone spline in YUV BT.2020. Per-pixel tone curves.
Standard DiT Block → Luma-MMDiT Block
Three targeted modifications — only colored parts are trainable (~17M / 12B)
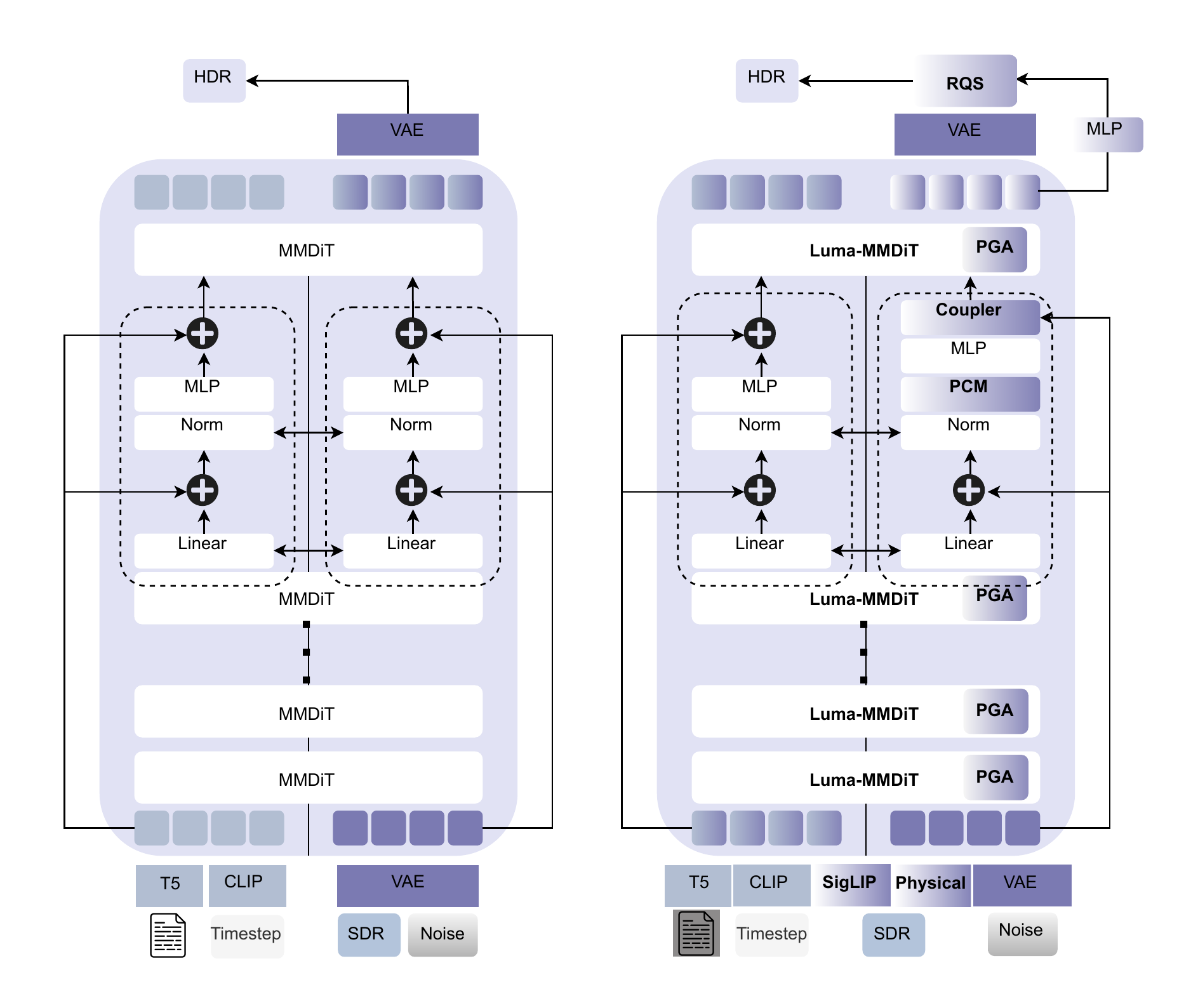
Left: Standard MMDiT. Right: Luma-MMDiT with PGA on value projection, PCM after norm, Coupler at output.
// Standard MMDiT block
z → LN(z)
Q = zWQ, K = zWK
V = zWV
h = Attn(Q,K,V)
z = z + h + MLP(LN(z))
// + Luma-MMDiT:
V = z(WV0 + Rvt,ℓ) ← PGA
h = γt,ℓ⊙LN(h) + ζt,ℓ ← PCM
z += λ(WpTphys + WcC(Tperc)) ← Coupler
TLAM: Ψ(t, ℓ) → 6 scalars
[αpga, βpga, αpcm, βpcm, nspec, λ]
Early steps → global tone. Late steps → highlight detail.
PGA: Physically-Guided Adaptation — Step by Step
Step 1: Extract physical features
Step 2: Physical & spectral gating
Step 3: Modulated LoRA
Three multiplicative modulations:
TLAM (α, β) — Timestep-layer scaling. Early = global tone. Late = highlights.
Gphys — Per-head luminance-aware gating. Sigmoid: 0=suppress, 1=pass.
gFFT — Frequency-aware gating. Prevents over-expansion in smooth (low-freq) regions.
Key property: Unlike standard LoRA (static), PGA is input-dependent, timestep-adaptive, and frequency-aware. The same image region gets different adaptation at different diffusion timesteps.
PCM (Perceptual) & RQS (Decoder)
Perceptual Cross-Modulation
FiLM: scale & shift per dimension after layer norm. Enforces color constancy — e.g., brighten sky highlights without shifting skin tones.
RQS Tone-Field Decoder
K=8 knots, per-pixel learned (ξ, η, s).
Monotonic — preserves luminance ordering.
Differentiable & invertible.
Operates in YUV BT.2020 — separates luminance from chroma.
Total Loss
1.0·‖Ylin−Y*‖₁ + 0.5·‖xlin−x*‖₁ + 0.01·LsplineSpline Smoothness
Lspline = 1/(K−1) Σ(sk+1−sk)²Luminance (primary) + color (secondary) + curve smoothness (regularization). All in linear light (PQ EOTF decoded).
Training: Data & Configuration
~318K paired SDR-HDR images
| Source | Clips | Type |
|---|---|---|
| HIDRO-VQA | 411 | Professional |
| CHUG | 428 | User-generated |
| LIVE-TMHDR | 40 | Studio + expert SDR |
8 TMOs × 3 CRF levels
Reinhard · BT.2446a · BT.2446c+GM · BT.2390+GM · YouTube LogC · OCIOv2 · HC+GM · Expert Graded
Training Configuration
Backbone: Frozen Flux (12B) · Trainable: ~17M params
Optimizer: AdamW · lr=1e-4 · cosine + 5K warmup
Iterations: 200K · batch 16 · 4×H200 · ~48 GPU-hours
Inference: 40 Euler steps · prompt-free · ~8s per 1080p
Evaluation Benchmarks
HDRTV1K
1K pairs, 1080p
HDRTV4K
4K resolution
Luma-Eval
20 unseen · 8 TMOs
New benchmark
Metrics: PSNR (PQ), SSIM, HDR-VDP-3, ΔEITP (ICtCp color difference)
Results: State-of-the-Art on All Benchmarks
| Method | 1K PSNR↑ | 1K SSIM↑ | 4K PSNR↑ | VDP3↑ | ΔEITP↓ |
|---|---|---|---|---|---|
| HDRTVNet++ | 38.36 | 0.973 | 30.82 | 8.75 | 8.28 |
| ICTCPNet | 36.59 | 0.922 | 33.12 | 8.57 | 7.79 |
| HDCFM | 38.42 | 0.973 | 33.25 | 8.52 | 7.83 |
| LEDiff | 36.52 | 0.872 | 32.25 | 5.71 | 9.13 |
| PromptIR | 32.14 | 0.954 | 28.48 | 9.17 | 9.59 |
| LumaFlux | 39.27 | 0.982 | 35.86 | 9.83 | 6.12 |
HDRTV1K
HDRTV4K
(best)
(best color)
First DiT-based ITM to beat all CNN & diffusion baselines. Strong 4K generalization despite 1080p training. Only ~17M trainable parameters on 12B frozen backbone.
Visual Result 1: Church Interior — Highlight Recovery

SDR Input (left half)
Stained-glass window clips to flat white. Gold ceiling mosaics lose all texture. 8-bit gamma collapses the entire highlight range.
LumaFlux HDR Output (right half)
Window highlights show gradual luminance roll-off. Gold leaf textures fully resolved. Zoomed inset reveals mosaic detail invisible in SDR.
Why this matters
~3 stops of highlight info destroyed by SDR clipping. PGA selectively expands highlights while PCM preserves warm color temperature of the gold mosaic.
Visual Result 2: Shanghai Cityscape — Shadow & Neon Recovery
SDR input (left) vs LumaFlux HDR output (right) — split view with zoomed crop below

SDR input (left half)
Pudong waterfront is near-black. Neon signs washed out. Zoomed crop shows boat and tower as indistinguishable dark blobs.
LumaFlux output (right half)
Neon signs vivid with accurate colors. Water reflections reveal full skyline. Zoomed crop shows sharp boat details, tower structure, and signage.
How LumaFlux handles this
PGA spectral gating amplifies shadow signal without artifacts. RQS decoder expands shadows/highlights via per-pixel monotone splines. PCM maps neon colors to correct BT.2020 gamut.
Ablation: Every Component Is Justified
Progressive addition of components on Luma-Eval benchmark (100K iterations)
| Configuration | PSNR↑ | ΔEITP↓ | VDP3↑ | ΔPSNR |
|---|---|---|---|---|
| Flux + LoRA | 33.42 | 8.58 | 7.82 | — |
| + PGA (no spectral) | 34.94 | 7.62 | 8.18 | +1.52 |
| + spectral gating | 35.18 | 7.31 | 8.29 | +0.24 |
| + PCM | 35.89 | 6.78 | 8.46 | +0.71 |
| + RQS (linear) | 35.72 | 6.85 | 8.41 | −0.17 |
| + RQS (monotone) | 35.98 | 6.09 | 8.61 | +0.26 |
Total: +2.56 dB over vanilla LoRA baseline
ΔPSNR contribution breakdown
Key findings
PGA is the largest contributor (+1.52 dB) — physical luminance features are critical. PCM adds +0.71 dB — perceptual semantics complement physics. RQS monotone > linear — monotonicity constraint prevents tone reversal and improves ΔEITP by 0.76.
User Study: Expert Perceptual Evaluation
10 experts, 10 HDR clips, 5-point MOS on calibrated HDR display (LG OLED, 1000 nits)
LumaFlux wins on all three criteria
Color fidelity: 4.5/5 — experts noted accurate neon reproduction, no hue shifts, stable skin tones. Overall: 4.2/5 — highest across brightness, color, and overall quality.
LEDiff is competitive on overall (4.0)
But loses on brightness (3.1 vs 3.8) — diffusion hallucination produces plausible-looking but physically inaccurate luminance. LumaFlux's PGA prevents this.
Classical BT.2446c trails on everything
Content-blind tone curves cannot compete with learned, physically-guided reconstruction. Overall: 2.7/5.
What We Learn & Remaining Challenges
Key insights
- Physical conditioning is the largest contributor (+1.52 dB from PGA alone). Luminance-aware gating is more valuable than semantic priors for ITM.
- Spectral gating prevents over-expansion in smooth regions. Frequency analysis is a natural complement to spatial features.
- Monotone RQS outperforms linear expansion. Enforcing physical constraints (monotonicity) improves both metrics and perceptual quality.
- ~17M parameters suffice to adapt a 12B backbone. The pretrained visual priors in Flux are extremely powerful — the key is steering them with physics.
Remaining challenges
- No temporal consistency — frame-by-frame processing. Video ITM needs temporal attention.
- VAE bottleneck — Flux VAE is trained for SDR. Fine-grained HDR detail may be lost in latent space.
- Inference speed — 40 ODE steps at ~8s/frame. Not yet real-time. Distillation is a clear next step.
Key Takeaways
First physically-guided DiT for inverse tone mapping. Luminance, gradients, spectra injected directly into attention via gated LoRA.
~17M trainable on 12B frozen. Parameter-efficient adaptation that preserves Flux's visual priors while adding physical grounding.
SOTA on all benchmarks, all metrics. +0.85 dB HDRTV1K, +2.61 dB HDRTV4K. 91% human preference over classical methods.
RQS decoder ensures physically valid tone expansion. Monotone, differentiable, per-pixel — eliminates banding while preserving highlights.
Next: Temporal LumaFlux for video · Model distillation for real-time · HDR-Q as perceptual reward model for LumaFlux → closing the perception-generation loop.
Part II: Generative Enhancement
Rectified-CFG++: Geometry-Aware Flow Guidance
On-manifold predictor-corrector guidance for rectified flow models
NeurIPS 2025
Why does guidance break on the
best image generators?
Flux, SD3, SD3.5 use rectified flows — deterministic ODE.
Standard CFG pushes trajectories permanently off-manifold.
Why Do We Need Guidance At All?
Without guidance, flow models generate plausible but generic images that loosely match the prompt
The problem with unconditional generation
Models trained with conditioning dropout learn both p(x|y) and p(x). Without guidance, outputs come from a mixture of conditional and unconditional — resulting in low prompt adherence, muted details, and bland compositions.
What guidance should do
Amplify the conditional signal — push generation toward what the prompt describes. Sharper details, more vivid colors, better text-image alignment. This is what CFG achieves in diffusion models (DDPM, SDXL).
What actually happens on flow models
CFG was designed for stochastic SDE samplers. Flow models use deterministic ODE. The extrapolation that works in SDEs becomes catastrophic in ODEs — artifacts, color blow-out, structural distortion.
Flux-dev: Same prompt, same seed
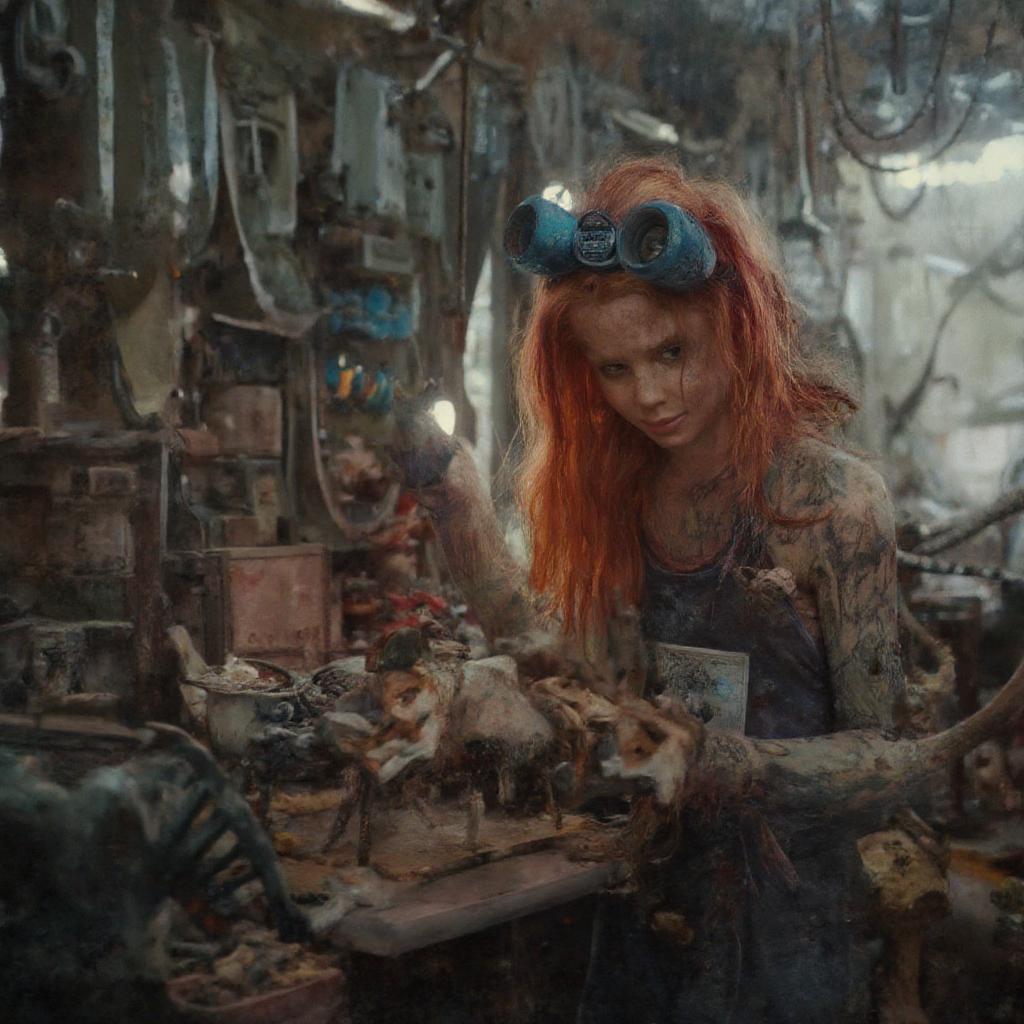
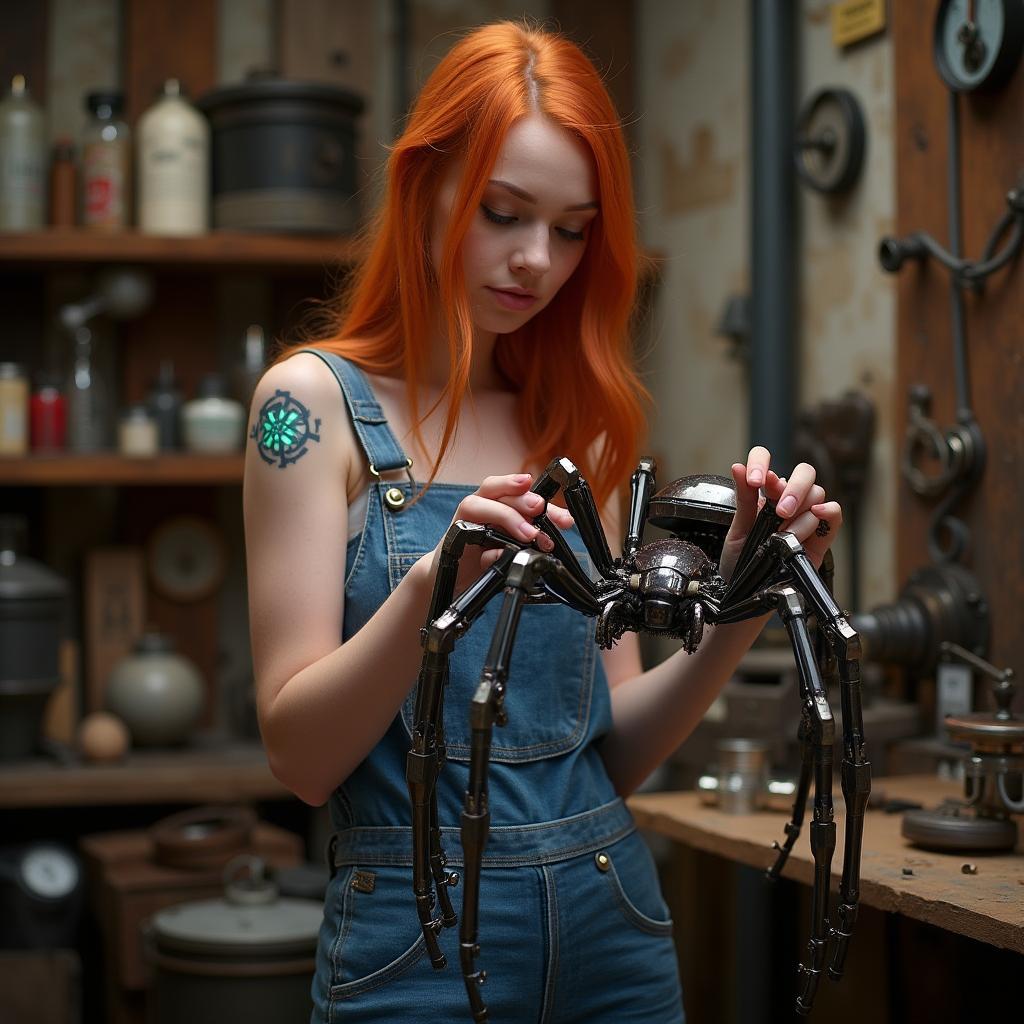

No guidance: dark, muddy, poor prompt adherence. CFG: oversaturated, unnatural. Ours: clean, natural, faithful.



SD3.5: Same pattern — CFG oversaturates, ours stays natural.
CFG Artifacts on Flow Models: A Gallery of Failures
All images generated with standard CFG on flow models. These are not cherry-picked — this is what CFG does to every prompt.
Flux-dev with CFG ω=3 (from paper Figure 6)





SD3 with CFG ω=3–3.5





Common failure modes: (1) Oversaturation — colors beyond natural range. (2) Cartoonification — photorealistic becomes plastic. (3) Text corruption — letters distort. (4) Detail blowout — textures replaced by flat patches.
Not rare failures. CFG artifacts appear on every prompt across Flux, SD3, and SD3.5. The problem is fundamental: CFG extrapolation is incompatible with deterministic ODE.
Root Cause: Why CFG Breaks on Flows but Works on Diffusion
The same extrapolation trick, but fundamentally different samplers
Obviously broken: CFG on SD3 & Flux


Garbled text ("Cyberre Cidie"), misspellings ("Entφy amd"), plastic cartoonification — all from standard CFG.
SDE Sampler (Diffusion) vs ODE Sampler (Flows)
Diffusion SDEs: built-in safety net
Each step adds Gaussian noise — the renoising step. This noise accidentally provides error correction: even when CFG pushes off-manifold, the stochastic noise partially pulls the sample back toward the learned distribution.
Discrete (DDPM): xt-1 = μθ(xt, t) + σt·z, z ~ N(0, I). The σt·z term adds fresh noise at every step — pulling samples back toward the learned distribution.
Flow ODEs: no correction mechanism
Rectified flows use a purely deterministic ODE. Once CFG pushes the trajectory off the manifold at step t, there is no mechanism to return. The off-manifold point becomes the starting point for step t+1.
Compounding error
At each step, CFG evaluates guidance at an off-manifold point — making the velocity direction even more wrong. Errors accumulate monotonically across all N sampling steps. The more steps, the worse it gets.
This is why we need a fundamentally different approach — not a fix for CFG, but a new guidance paradigm designed specifically for deterministic ODE samplers.
What Would an Ideal Guidance Method Look Like?
Desiderata for guidance on rectified flow models
D1: Stay on the manifold
The guided trajectory must remain in a bounded neighbourhood of the learned transport manifold Mt. No off-manifold drift, no error accumulation.
D2: Adaptive — strong early, gentle late
Early steps determine global structure (layout, color palette) — guidance should be strong. Late steps resolve fine details (text, textures) — guidance should vanish to prevent corruption.
D3: Provable guarantees
Not just empirically better — we want formal bounds on manifold distance and distributional deviation. No prior guidance method provides this.
D4: Drop-in replacement
Works with any pretrained flow model — Flux, SD3, SD3.5, Lumina — without retraining. Just swap the sampling algorithm.
Do existing methods satisfy these?
| Method | D1 | D2 | D3 | D4 |
|---|---|---|---|---|
| CFG | ✗ | ✗ | ✗ | ✓ |
| CFG-Zero* | ✗ | ✗ | ✗ | ✓ |
| APG | ~ | ✗ | ✗ | ✓ |
| Rect-CFG++ (Ours) | ✓ | ✓ | ✓ | ✓ |
Our key insight: Don't extrapolate the guidance direction from the current point. Instead, predict a midpoint on the manifold, evaluate guidance there, and apply it as a bounded additive correction to the conditional velocity.
Three ideas → three guarantees:
Predictor half-step (on-manifold evaluation) + Adaptive α(t) (vanishing guidance) + Bounded correction (interpolation not extrapolation)
The Geometric Insight: Why CFG Fails and How We Fix It
Three panels: (Left) Ideal flow on manifold. (Center) CFG extrapolates off-manifold. (Right) Rect-CFG++ stays on-manifold via predictor-corrector. Let's walk through each.
Why does CFG work in diffusion but not in flows?
In diffusion models (SDE samplers like DDPM), each step adds stochastic noise — the renoising step. This noise acts as implicit error correction: even if CFG pushes the trajectory off-manifold, the added noise partially brings it back. It's a built-in safety net.
In rectified flow models (ODE solvers like Flux), sampling is purely deterministic — there is no renoising step. Once CFG pushes the trajectory off the manifold, there is no mechanism to return. The error at step t becomes the starting point for step t-1, and the next CFG extrapolation makes it worse. Errors accumulate monotonically across all sampling steps.
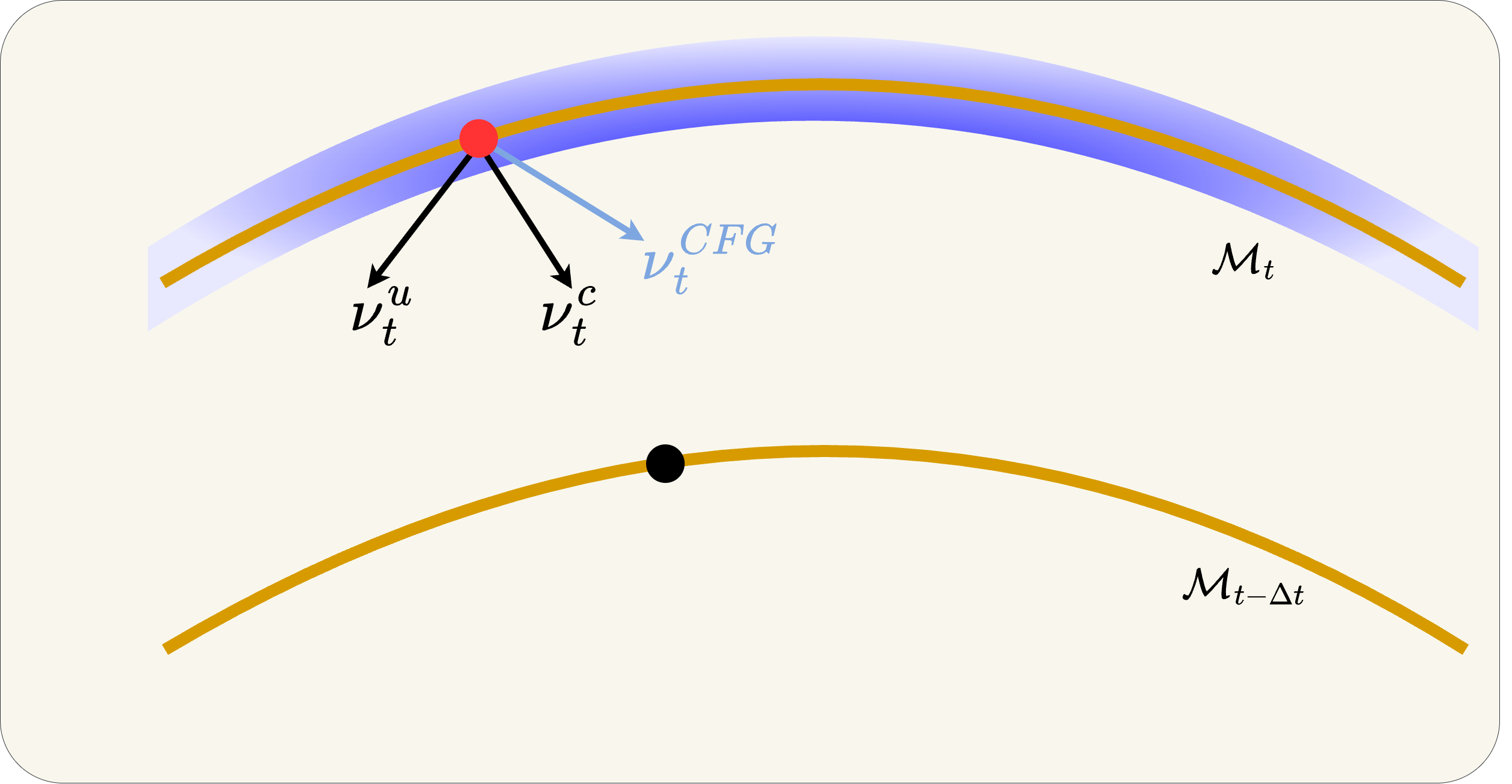
Geometric Insight (1/3): The Ideal Flow on the Manifold


What you're seeing
Three manifolds: Mt (current time, blue/gold band), Mt-1 (next step), M0 (data, orange curve at bottom). The red dots are the ideal positions at each timestep.
The ideal trajectory
The ideal sample flows along the manifold surface from Mt → Mt-1 → M0. At each step, the velocity lies in the tangent space of the manifold — never leaving it.
Three flows shown
Blue = Flux conditional (vc), Red = CFG (extrapolated), Green = Rectified-CFG++ (ours). Notice how green and blue stay near the manifold while red diverges.
Key question
How do we guide the generation (improve text adherence) while staying on the manifold? Let's see what goes wrong first...
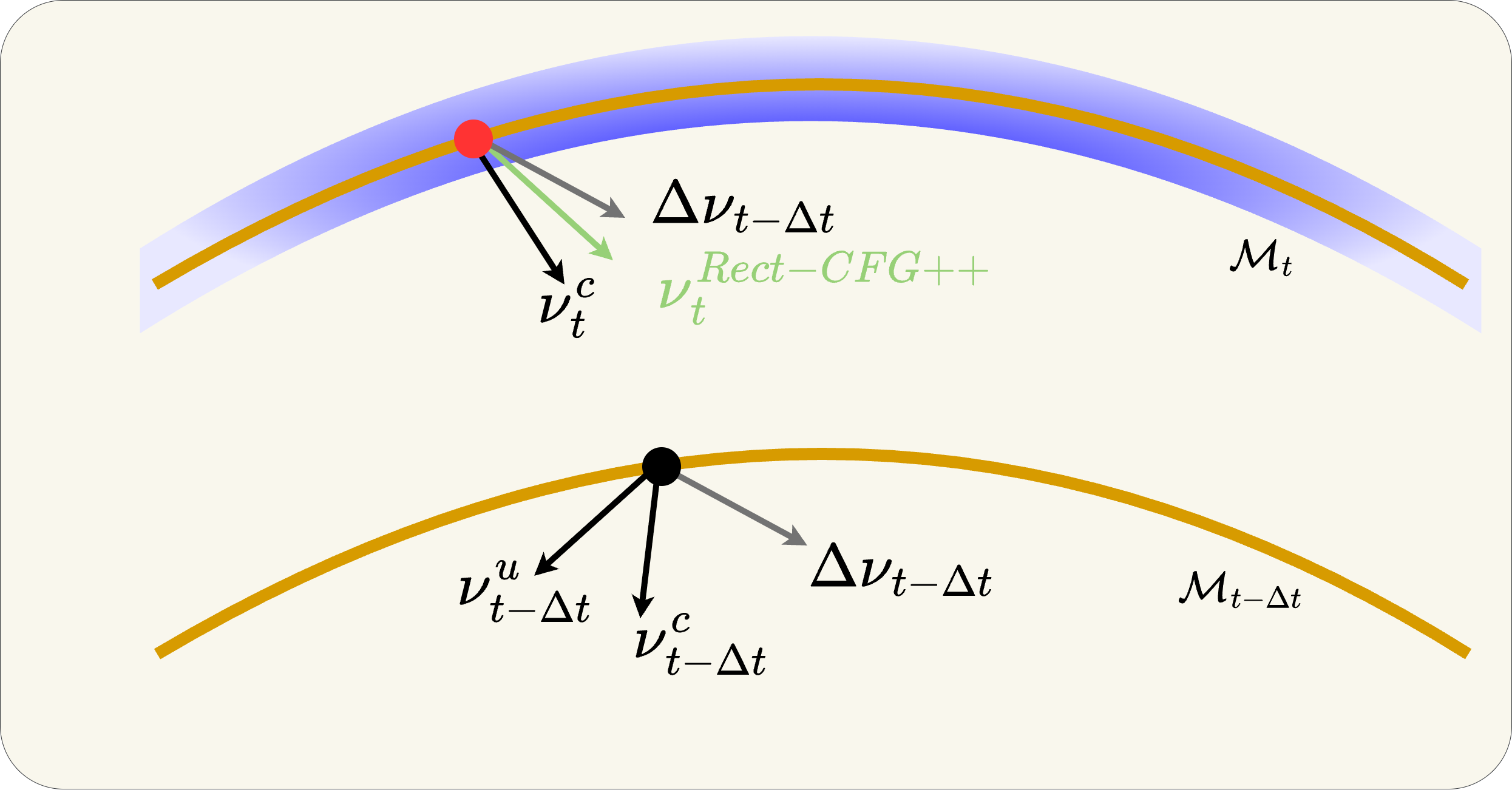
Geometric Insight (2/3): CFG Extrapolates Off-Manifold
What CFG does
Starting from the black dot on Mt, CFG computes the guided velocity v̂ω at the current point. With ω>1, this velocity extrapolates past the conditional velocity vc.
The tangent space violation
The guided velocity v̂ω does not belong to the tangent space TxtMt. The resulting Euler step lands the sample off Mt-1. In a deterministic ODE, there is no mechanism to return.
The compounding effect
At the next step, CFG evaluates guidance at the off-manifold point — making the direction even worse. Errors accumulate at every step. By the final image: oversaturation, color blow-out, structural distortion.
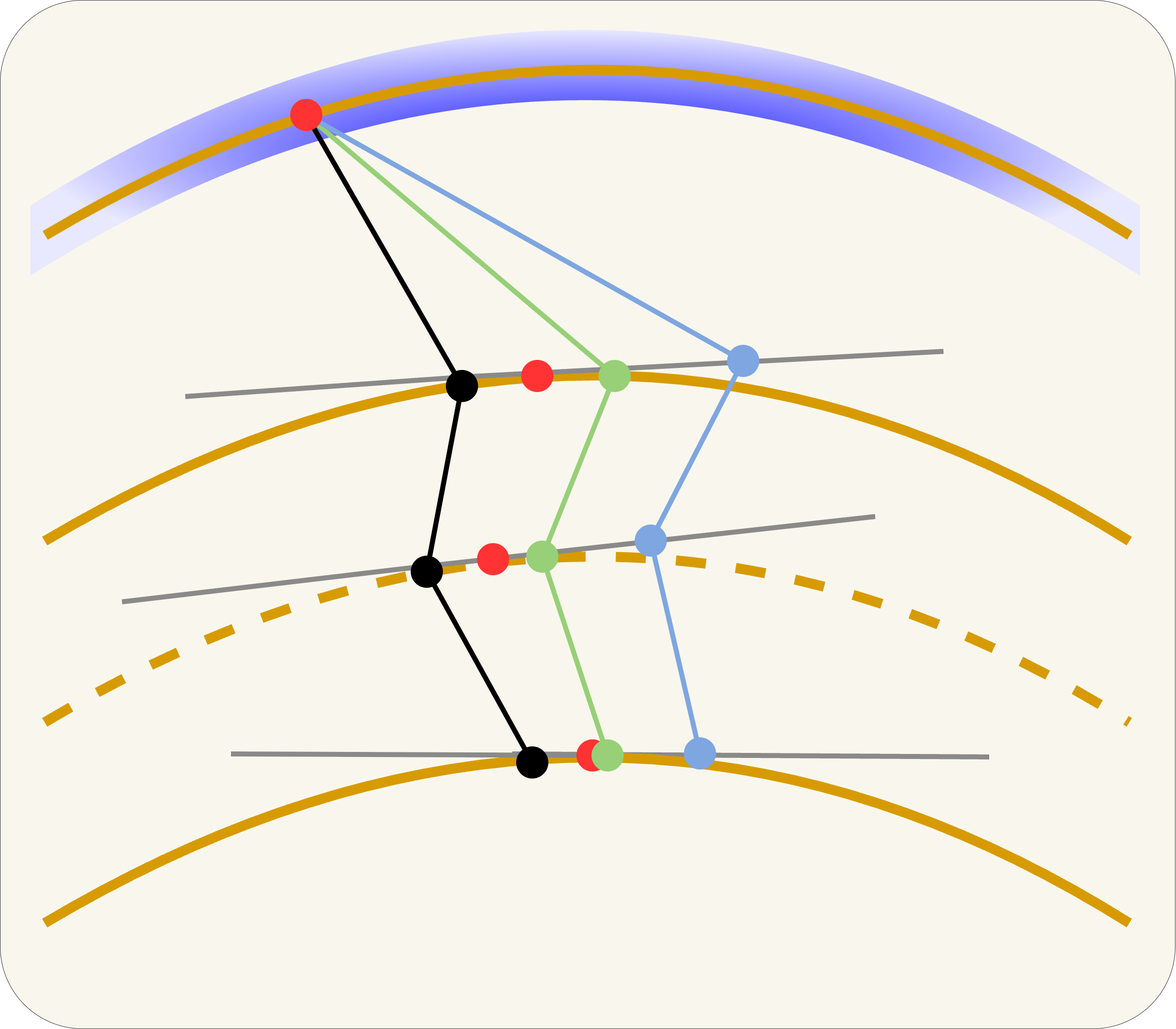
Geometric Insight (3/3): Our Predictor-Corrector Stays On-Manifold
Step 1: Predict midpoint with vc only
Take a half-step using only the conditional velocity: x̃mid = xt + (Δt/2)·vct. Since vc lies in the tangent space, x̃mid lands on or near Mt-Δt/2.
Step 2: Evaluate guidance at the predicted midpoint
Compute vcmid and vumid at x̃mid. The guidance direction Δvmid = vcmid − vumid is evaluated on the manifold, reflecting the geometry of the target manifold Mt-Δt.
Step 3: Apply bounded interpolative correction
α(t) = λmax(1-t)γ. Base velocity is always vc (on manifold). Correction is additive and bounded. α(t)→0 near data → fine details preserved.
Result: trajectory stays in bounded tubular neighbourhood of Mt
The Core Distinction: Extrapolation vs. Interpolation
This single difference explains why CFG fails and Rect-CFG++ works
CFG: Extrapolation (ω > 1)
CFG moves PAST the conditional direction.
ω=3 means 3× the distance from vu to vc. Overshoots into unknown territory.
Ours: Interpolation (0 ≤ α ≤ 1)
Ours stays BETWEEN vc and vc+Δv.
Base is always vc (on manifold). Correction α(t)·Δvmid is bounded and decays to 0 near data.
Algorithm: CFG vs. Rectified-CFG++ (Side-by-Side)
Color highlights show exactly what changes — green = our additions
Standard CFG Sampling
for t = T down to 1:
vc = vθ(xt, t, y)
vu = vθ(xt, t, ∅)
v̂ = vu + ω(vc − vu) ← extrapolation!
xt-1 = xt + Δt · v̂
2 NFE/step. ω>1 pushes off manifold. No correction.
Rectified-CFG++ (Ours)
for t = T down to 1:
vc = vθ(xt, t, y)
x̃mid = xt + (Δt/2)·vc ← predictor
vcmid = vθ(x̃mid, t-Δt/2, y)
vumid = vθ(x̃mid, t-Δt/2, ∅)
v̂ = vc + α(t)(vcmid − vumid) ← interpolation!
xt-1 = xt + Δt · v̂
3 NFE/step. α(t)=λ(1-t)γ decays → on-manifold. Bounded.
Key differences: (1) Base velocity is always vc, not extrapolated. (2) Guidance evaluated at predicted midpoint on manifold, not current point. (3) Adaptive α(t) → 0 near data.
Guidance Methods Compared: Equations & Properties
Four approaches to the same problem — only ours avoids extrapolation entirely
Standard CFG (Ho & Salimans, 2022)
ω > 1 → extrapolation past vc. Designed for SDEs with renoising. On ODEs: off-manifold drift, oversaturation, error accumulation. Constant guidance at all timesteps.
CFG-Zero* (Wang et al., 2024)
Adds an optimal rescaling factor st* to align unconditional/conditional norms. Reduces initial drift but still extrapolates (ω > 1). No late-step adaptation — fine details still corrupted.
APG (Sadat et al., 2024)
Projects guidance direction onto perpendicular subspace to reduce parallel component. Partial mitigation but guidance still evaluated at current point (possibly off-manifold). No decay schedule, no formal bounds.
Rectified-CFG++ (Ours)
Three key differences: (1) Base = vc always (on-manifold). (2) Guidance at predicted midpoint x̃mid (on-manifold). (3) α(t) = λ(1-t)γ → 0 near data. Bounded, interpolative, provable.
| Property | CFG | CFG-Zero* | APG | Ours |
|---|---|---|---|---|
| Guidance type | Extrapolation | Extrapolation | Projection | Interpolation |
| Evaluated at | Current xt | Current xt | Current xt | Predicted x̃mid |
| Temporal schedule | None (constant) | None | None | α(t) → 0 |
| Formal guarantees | ✗ | ✗ | ✗ | ✓ (3 props) |
| NFE per step | 2 | 2 | 2 | 3 |
Theoretical Guarantees — First Provable Bounds for Flow Guidance
Four mild assumptions → three rigorous guarantees. No prior guidance method has these.
Assumptions
(A1) vθ(x,t,y) and vθ(x,t,∅) are L-Lipschitz in x
(A2) Guidance direction bounded: ‖Δvtθ(x)‖ ≤ B
(A3) Schedule α(t) is bounded and integrable
(A4) Conditional velocity bounded: ‖vct‖ ≤ Vmax
All standard regularity conditions. Lipschitz and boundedness are satisfied by any well-trained neural network. No exotic assumptions needed.
Lemma 1: Guidance Stability
Guidance direction at the predicted midpoint differs from guidance at current point by only O(Δt). The predictor doesn't introduce large errors.
Proposition 1: Bounded Single-Step Perturbation
Deviation from the pure conditional path is controlled by α(t) at each step. Since α(t) → 0 as t → 0, perturbations vanish near the data manifold.
Proposition 2: Distributional Deviation
Total KL divergence controlled by integrated guidance ∫α(τ)dτ — the single quantity that determines output quality.
Why These Guarantees Matter: CFG vs. Ours
Lemma 2: Manifold-Faithful Corrector
Distance to manifold bounded by training error ε only. The corrector displacement is tangent to Mt-Δt/2 — guidance doesn't push off-manifold.
Integrated Guidance: The Key Quantity
Head-to-Head: Every Property
| Property | CFG | Ours |
|---|---|---|
| Per-step perturbation | (ω−1)·B·Δt constant, never vanishes | α(t)·B·Δt → 0 near data |
| Manifold distance | Unbounded errors accumulate | O(ε·Δt) training error only |
| Integrated guidance | ω−1 ≈ 2–8 | λ/(γ+1) ≈ 0.5 |
| KL(p̂₀ ‖ p₀) | O(ω−1) | O(0.5) |
| Late-step behavior | Same ω everywhere → destroys fine details | α(t) → 0 → preserves fine details |
| Guidance evaluation | At current point (possibly off-manifold) | At predicted midpoint (on manifold) |
Bottom line: CFG has no convergence guarantee for flow models. Ours proves that the output distribution deviates from the true conditional distribution by a controllable, bounded amount — proportional to ∫α(τ)dτ which we set to ≈0.5.
Intermediate Denoising: Watching Artifacts Grow vs. Stay Clean
Each strip shows 7 denoising steps from noise (left) to final image (right)
Standard CFG (ω=2.5) — artifacts compound


Rectified-CFG++ (λ=0.5) — clean throughout


CFG: Off-manifold drift begins at early steps (step 2-3). By mid-trajectory, color artifacts are baked in. Late steps cannot correct — each step amplifies the error. The final image has oversaturated colors and unnatural contrast.
Ours: Predictor step keeps each intermediate on Mt. α(t) schedule applies strong guidance early (global structure) and vanishes late (fine details). Result: every intermediate looks natural. No error accumulation.
2D Toy: CFG Drifts Off-Support, Ours Stays On-Manifold
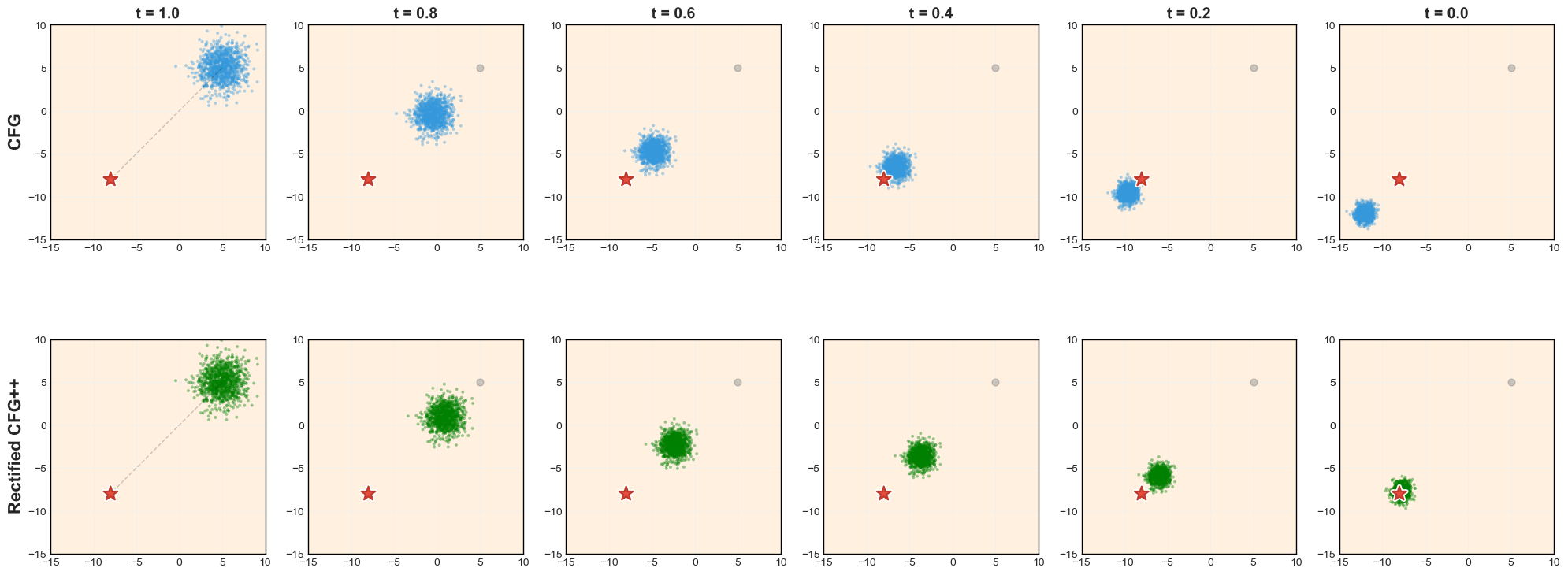
200 trajectories on 2D mixed Gaussian. Top: CFG (blue) drifts off support. Bottom: Ours (green) smooth on-manifold.
CFG (top)
Trajectories initially overshoot, leaving the learned transport manifold. Sharp late-stage corrections pull samples back — but damage is done. Final distribution is noisy and off-center.
Rectified-CFG++ (bottom)
Smooth convergence throughout. Predictor anchors each step on the flow field. Corrector applies bounded guidance. Samples arrive at target with tight concentration — no drift, no sharp corrections.
Flux: Baseline vs. CFG vs. Rectified-CFG++ (3 Prompts)

Top: Flux baseline (no guidance). Middle: CFG — oversaturated, cartoonish, structural distortion. Bottom: Rect-CFG++ — sharp details, faithful colors, correct structure.
Cactus: CFG turns photorealistic cactus into cartoon with emoji-like face. Ours preserves desert realism.
Dog + moon gate: CFG loses the stone arch, replaces with painted mountains. Ours preserves the gate structure and moon.
Parrot: CFG turns the bird into a psychedelic abstraction. Ours preserves natural plumage and forest setting.
Flux: Baseline vs. CFG vs. Rectified-CFG++ (Same Prompt, Same Seed)

Same model (Flux-dev), same prompt, same seed — three guidance strategies. Left: no guidance (baseline). Center: CFG (ω=3.5). Right: Rectified-CFG++ (λ=0.5). Ours: sharper details, faithful colors, no rainbow artifacts.
Diverse Prompt Gallery: Rectified-CFG++ Handles Everything
All images generated with Rectified-CFG++ on Flux-dev. No cherry-picking — random prompts from MS-COCO and Pick-a-Pic.

Photorealistic scenes
Landscapes, portraits, food, architecture — natural lighting, correct shadows, no oversaturation. The on-manifold property preserves the photorealistic distribution Flux was trained on.
Artistic & stylized
Oil paintings, digital art, fantasy scenes — style transfer works correctly because α(t) allows strong guidance early (global style) while preserving fine brush strokes late.
Text & compositional
Signage, book titles, multi-object scenes — the hardest category for any guidance method. α(t)→0 at late steps preserves pixel-precise text rendering and spatial relationships.
SD3.5: 4-Way Guidance Comparison (Same Prompt, Same Seed)








Flux-dev: CFG vs. Ours (8 Comparisons)




More Visual Comparisons: SD3 & Lumina-Next








Drop-in replacement across all rectified flow models — no retraining, no arch changes.
Text Rendering: The Stop Sign Test
Text-heavy prompts are especially sensitive to off-manifold drift at late denoising steps
CFG

Rectified-CFG++

Prompt: "A stop sign with 'ALL WAY' written below it."
CFG: "STOP" text distorts — letter shapes warp, "ALL WAY" becomes unreadable. Off-manifold drift corrupts high-frequency text strokes in the final denoising steps.
Ours: Crisp, photorealistic stop sign. α(t)→0 near t=0 ensures pure conditional flow during fine detail resolution — text strokes remain pixel-precise.
Text Rendering: Neon Street Sign
CFG
Rectified-CFG++

Prompt: "A neon street sign that says 'CyberCore Cafe', glowing in magenta and blue."
CFG garbles the neon letters — "Cyberre Cidie Cafe" instead of "CyberCore Cafe". Glow halos and letter boundaries bleed together. Ours renders each letter distinctly with clean neon glow separation.
Text Rendering: Headlines & Inscriptions
CFG

Ours

CFG

Ours

Prompt: "A crow detective reading a paper titled 'Feathered Conspiracies', headline in bold noir font."
Prompt: "A magical sword embedded in stone, with the name 'SOLARFANG' etched along its blade in glowing runes."
CFG: "Feathered Conspiracies" → "Feathhrad Conspiracies". "SOLARFANG" → garbled runes. Ours: Both headlines render correctly with proper typography — even on complex surfaces like aged paper and glowing stone.
Text Rendering: Presentations & Artistic Text
CFG
Ours

CFG

Ours

Prompt: "A fox giving a TED talk, slide behind reads 'Entropy and the Soul'."
Prompt: "A burning scroll with the title 'Soulbound by Nightfall' in ornate calligraphy."
CFG: "Entropy and the Soul" → "Entφy amd the Soul". Title on scroll barely readable. Ours: Clean title text on both the presentation screen and the burning scroll — fine details preserved by zero guidance at final steps.
Text Rendering: Carved & Printed Text
CFG

Ours

CFG

Ours

Prompt: "A desert gate carved in sandstone reading 'CITY OF WHISPERS'."
Prompt: "A Japanese fish stamp print with 'WAVES OF JUSTICE' in red ink."
Pattern: Across all text types — neon, carved stone, ink stamps, calligraphy, digital displays — Rectified-CFG++ preserves legibility. The adaptive schedule α(t)→0 is key: no guidance perturbation during fine-detail resolution.
Text Legibility: Full Gallery (SD3.5)
Each column: CFG left → Rectified-CFG++ right














Consistent text legibility across all prompts — the adaptive schedule α(t) is the key mechanism.
Quantitative: MS-COCO 10K — Consistent Improvements
| Model | Method | FID↓ | CLIP↑ | ImgRwd↑ | Pick↑ | HPS↑ |
|---|---|---|---|---|---|---|
| Lumina | CFG | 26.93 | 0.261 | 0.547 | 21.03 | 0.253 |
| Lumina | Ours | 22.49 | 0.268 | 0.621 | 21.19 | 0.259 |
| SD3 | CFG | 26.33 | 0.273 | 0.684 | 21.48 | 0.264 |
| SD3 | Ours | 24.68 | 0.278 | 0.753 | 21.62 | 0.269 |
| Flux | CFG | 37.86 | 0.285 | 0.892 | 22.04 | 0.279 |
| Flux | Ours | 32.23 | 0.289 | 0.961 | 22.18 | 0.283 |
| Guidance (SD3.5) | FID | ImgRwd | CLIP | HPSv2 |
|---|---|---|---|---|
| CFG | 67.71 | 1.053 | 0.352 | 0.294 |
| CFG-Zero* | 68.39 | 0.995 | 0.346 | 0.288 |
| APG | 67.23 | 1.075 | 0.351 | 0.294 |
| Rect-CFG++ | 67.15 | 1.085 | 0.351 | 0.296 |
Best or tied on every metric, every model.
User Study: 30 Experts × 32 Prompts × 4 Models = 15,360 Responses
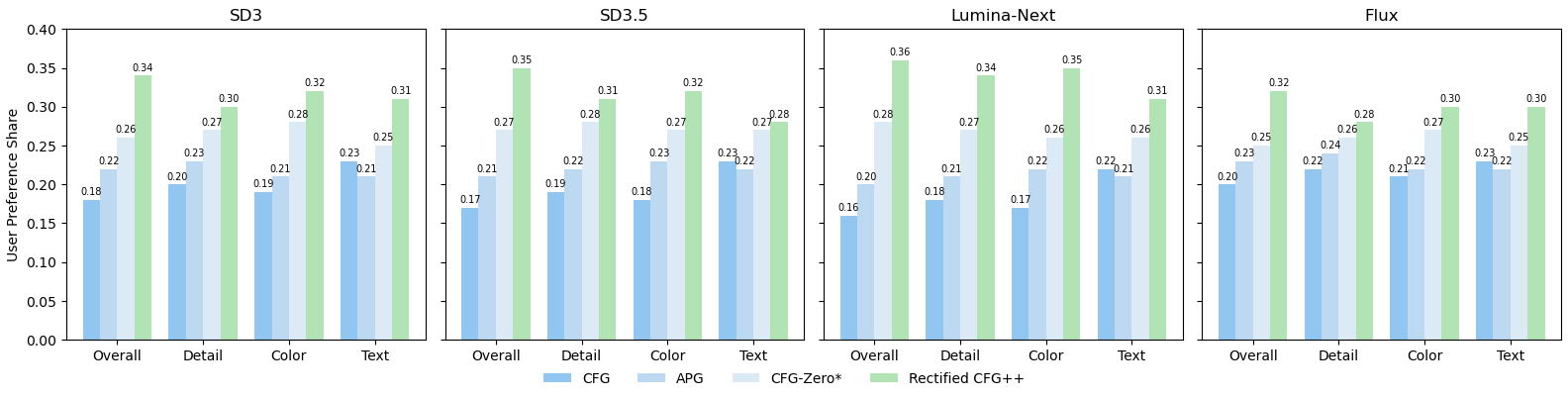
4-way forced choice: CFG (dark blue), APG (medium blue), CFG-Zero* (light blue), Rectified-CFG++ (green). 4 criteria × 4 models. Green bar is tallest in every single comparison.
Overall: 34-36% preference share across all models (random chance = 25%). p < 0.001 vs second-best (APG).
Text legibility: Highest improvement dimension — 28-32% vs 22-25% for alternatives. α(t) schedule is critical.
Protocol: Fleiss' κ = 0.61 (substantial agreement). Images randomized. Experts with CV/generative AI knowledge.
Ablation 1: Guidance Scale — CFG Crashes, Ours Stays Stable
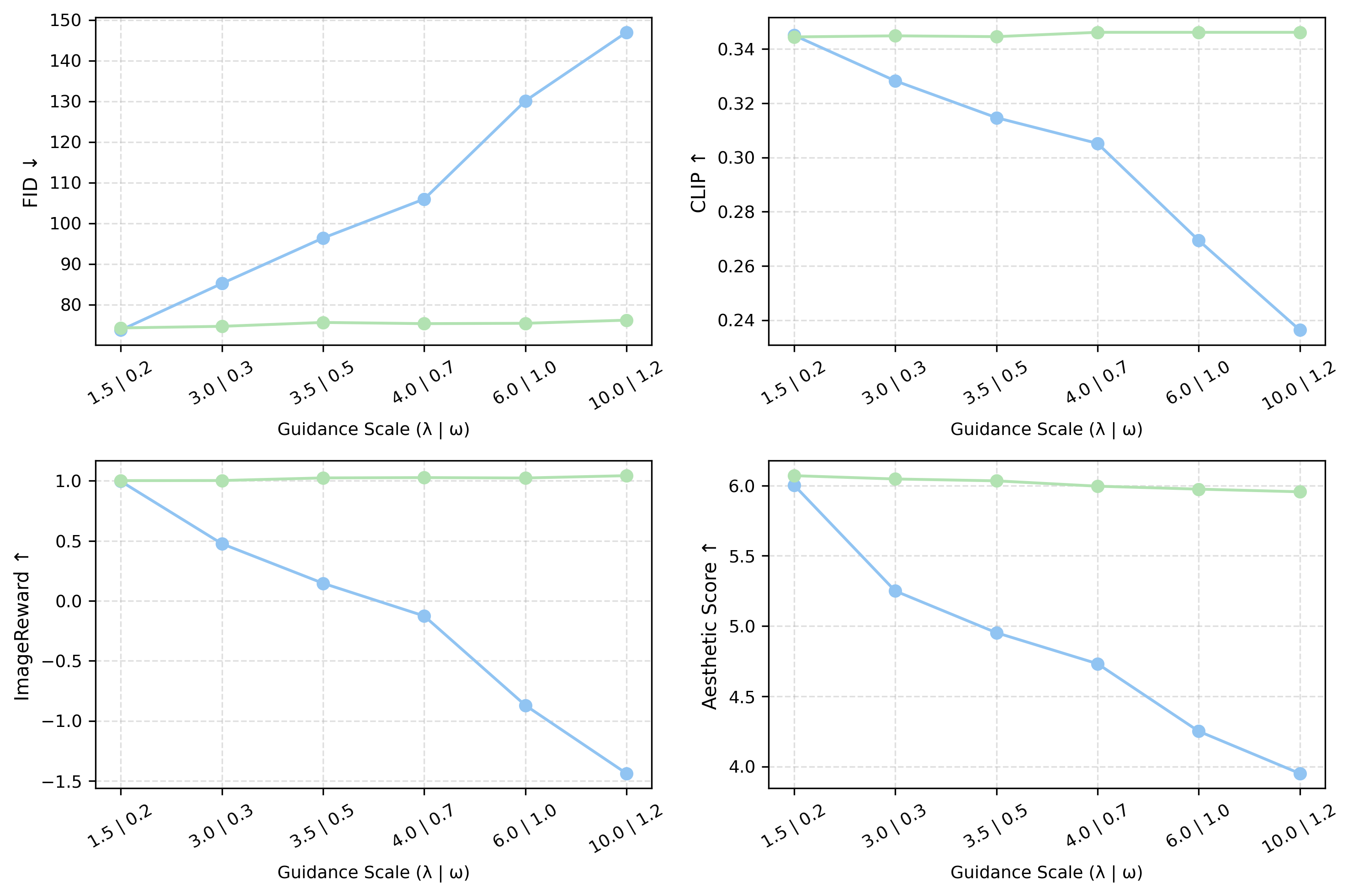
X-axis: guidance scale (λ for ours | ω for CFG). Y-axis: FID↓, CLIP↑, ImageReward↑, Aesthetic↑. Blue = CFG, Green = Ours.
CFG (blue curves)
FID explodes: 77 → 148 at ω=10. ImageReward collapses: 1.0 → -1.5. CLIP drops 30%. Aesthetic drops 35%. Catastrophic failure at high guidance.
Rectified-CFG++ (green curves)
FID: 75 → 75 (flat!). ImageReward: 1.0 → 0.95. CLIP stable. Aesthetic stable. Graceful degradation — never crashes.
Why this matters
CFG requires careful per-model tuning of ω to avoid collapse. Rect-CFG++ is robust across a 50× range of λ — no hyperparameter sensitivity. One setting works everywhere.
Ablation 2: Sampling Steps — Better Quality with Fewer Steps
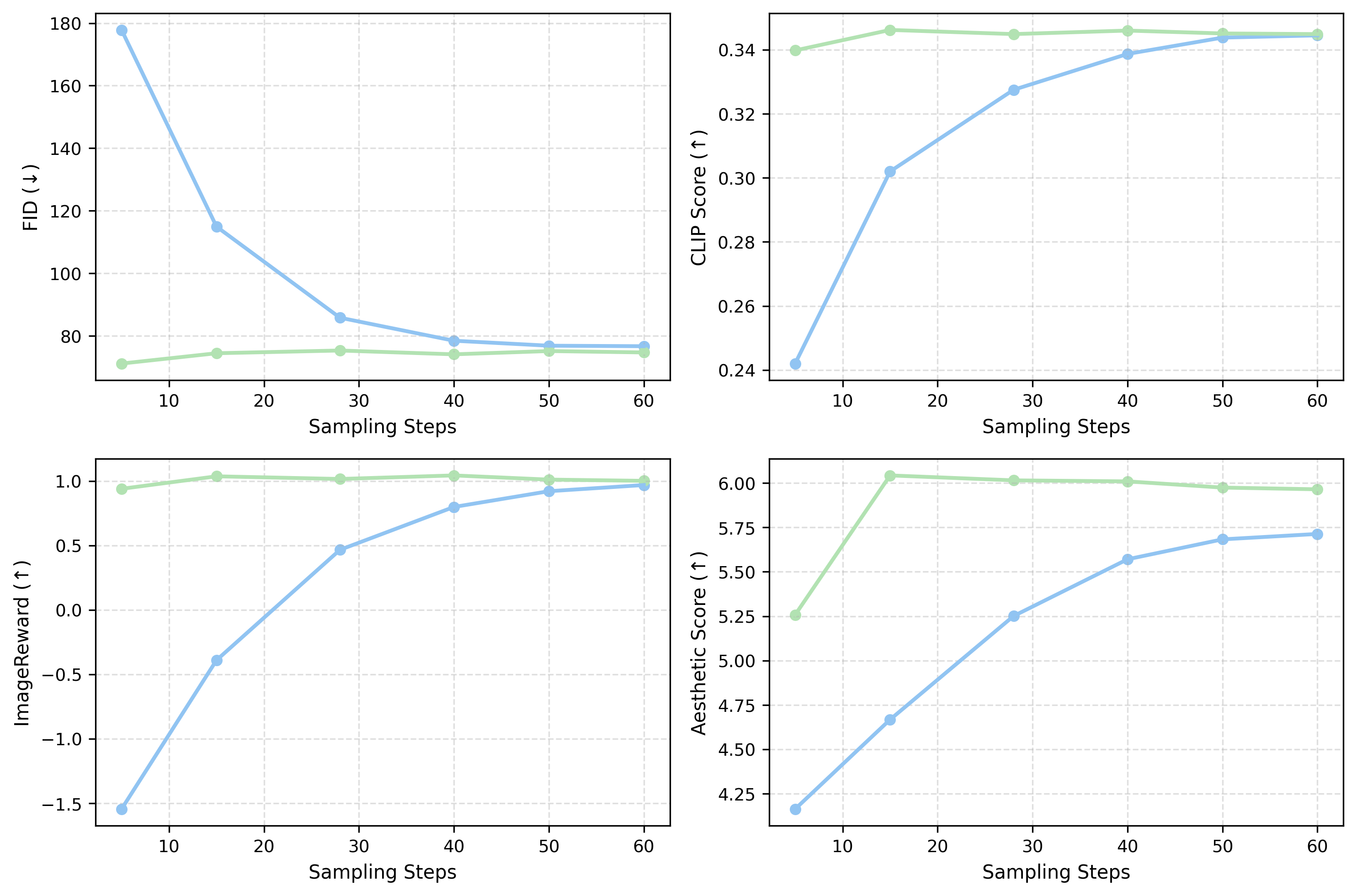
X-axis: sampling steps. Blue = CFG, Green = Ours. Our method converges faster across all metrics.
Ours at 5 steps vs CFG at 5 steps
FID: 71 vs 178 (2.5× better). ImageReward: 1.0 vs -1.5. At ultra-low NFE, CFG produces garbage; ours produces usable images.
Ours at 15 steps ≈ CFG at 28 steps
Same FID, same CLIP, same ImageReward — but ~2× faster inference. This is because our on-manifold trajectories converge more efficiently.
Component ablation (SD3.5)
| Config | FID | CLIP | HPSv2 |
|---|---|---|---|
| Unconditional only | 91.12 | 0.144 | 0.187 |
| w/o Predictor | 73.70 | 0.341 | 0.297 |
| w/o Corrector | 74.65 | 0.341 | 0.298 |
| Full | 72.97 | 0.345 | 0.300 |
Both predictor and corrector essential.
Key Takeaways
First on-manifold guidance for rectified flow models. Predictor-corrector with adaptive decay. Provably bounded manifold distance.
4-16× tighter distributional bounds than CFG. Three propositions with formal proofs. Integrated guidance λ/(γ+1) vs ω-1.
Universal drop-in, zero overhead. Flux, SD3, SD3.5, Lumina — all improve. No retraining. 15 steps ≈ CFG at 28.
43.5% preference, 15K expert responses. Best on detail, color, text, overall across all models. p < 0.001.
Next: Rect-CFG++ for video generation (Sora-class) · Distilled flow models · Integration with LumaFlux for guided HDR generation.
Summary of Contributions
HDR-Q
First MLLM for HDR VQA
HAPO: 3 novel RL mechanisms
Formal MI guarantee
0.921 SROCC
+8.2% over prior SOTA
Rect-CFG++
First on-manifold guidance for flows
Predictor-corrector + adaptive decay
Provable bounded deviation
43.5% preference
Drop-in, zero overhead
LumaFlux
First physics-guided DiT for ITM
PGA + PCM + RQS decoder
17M trainable / 12B frozen
+0.85 dB PSNR
SOTA on all 3 benchmarks
Foundation: Beyond8Bits (44K HDR videos, 1.5M+ ratings) · LGDM (zero-shot IQA, ICML '25) · HIDRO-VQA · BrightRate
Connecting the Contributions
Understanding perception enables guiding generation, which enhances perception.
Perceive
Beyond8Bits · LGDM
HDR-Q (MLLM + HAPO)
Guide
Rect-CFG++
On-manifold predictor-corrector
Enhance
LumaFlux
PGA + PCM + RQS
Generative priors are the common thread — pretrained models encode rich perceptual knowledge for both assessment and enhancement.
Publications
- 1. TABES: Trajectory-Aware Backward-on-Entropy Steering for Masked Diffusion Model [Under Review]
- 2. LumaFlux: Lifting 8-Bit Worlds to HDR Reality with Physically-Guided Diffusion Transformers [Under Review]
- 3. Seeing Beyond 8bits: Subjective and Objective Quality Assessment of HDR-UGC Videos [CVPR 2026]
- 4. BrightRate: Quality Assessment for User-Generated HDR Videos [WACV 2026] (Oral / Best Paper Award)
- 5. Rectified CFG++ for Flow Based Models [NeurIPS 2025]
- 6. LGDM: Latent Guidance in Diffusion Models for Perceptual Evaluations [ICML 2025]
- 7. CHUG: Crowdsourced User-Generated HDR Video Quality Dataset [IEEE ICIP 2025]
- 8. HIDRO-VQA: Deep Contrastive Representation Learning for HDR Video Quality Assessment [WACV 2024]

Questions?
Thank You!
Perceptual Quality Assessment and Enhancement
of Visual Media using Generative Priors
Shreshth Saini
PhD Candidate
✉ shreshth@utexas.edu
► Slides: shreshthsaini.github.io/slides/defense.html
Laboratory for Image & Video Engineering (LIVE)
The University of Texas at Austin
Advised by Prof. Alan C. Bovik