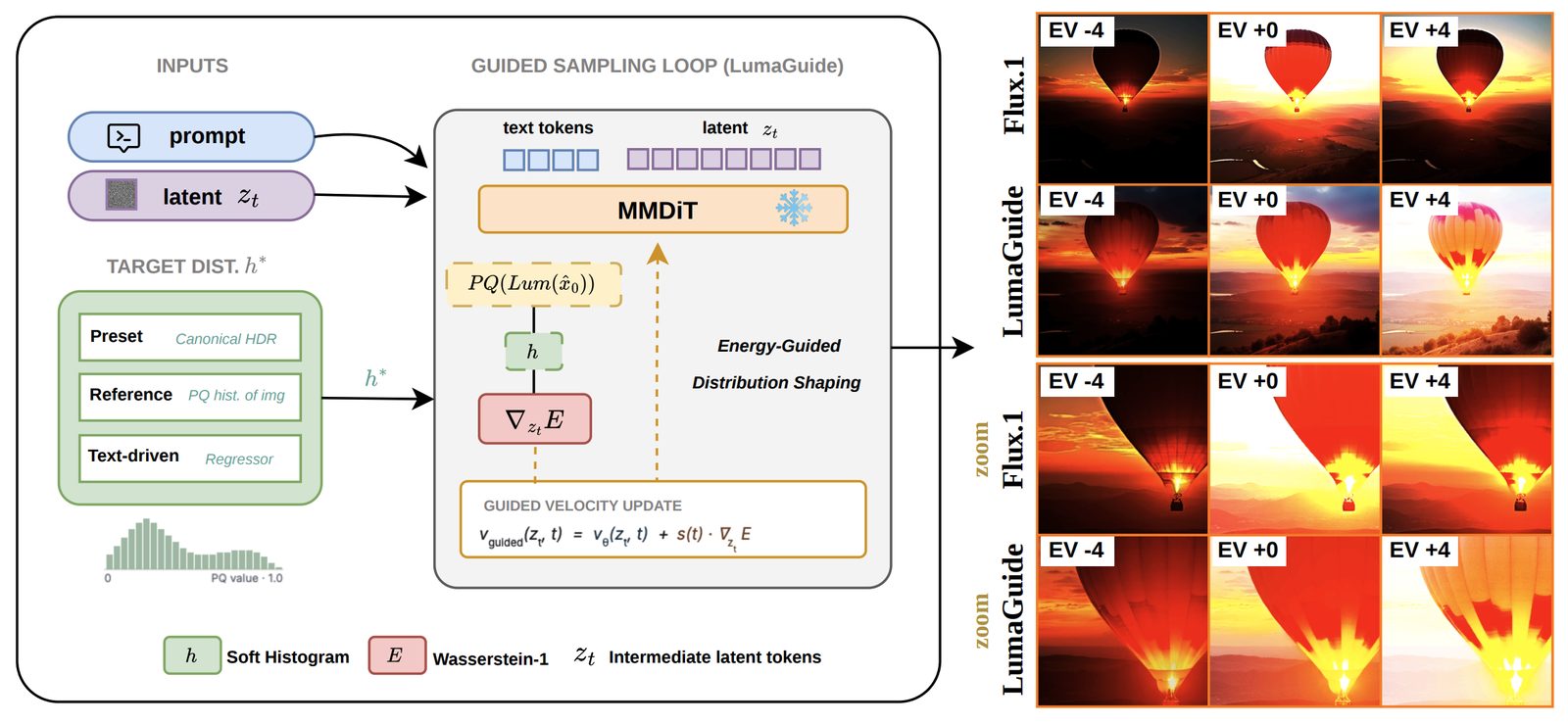
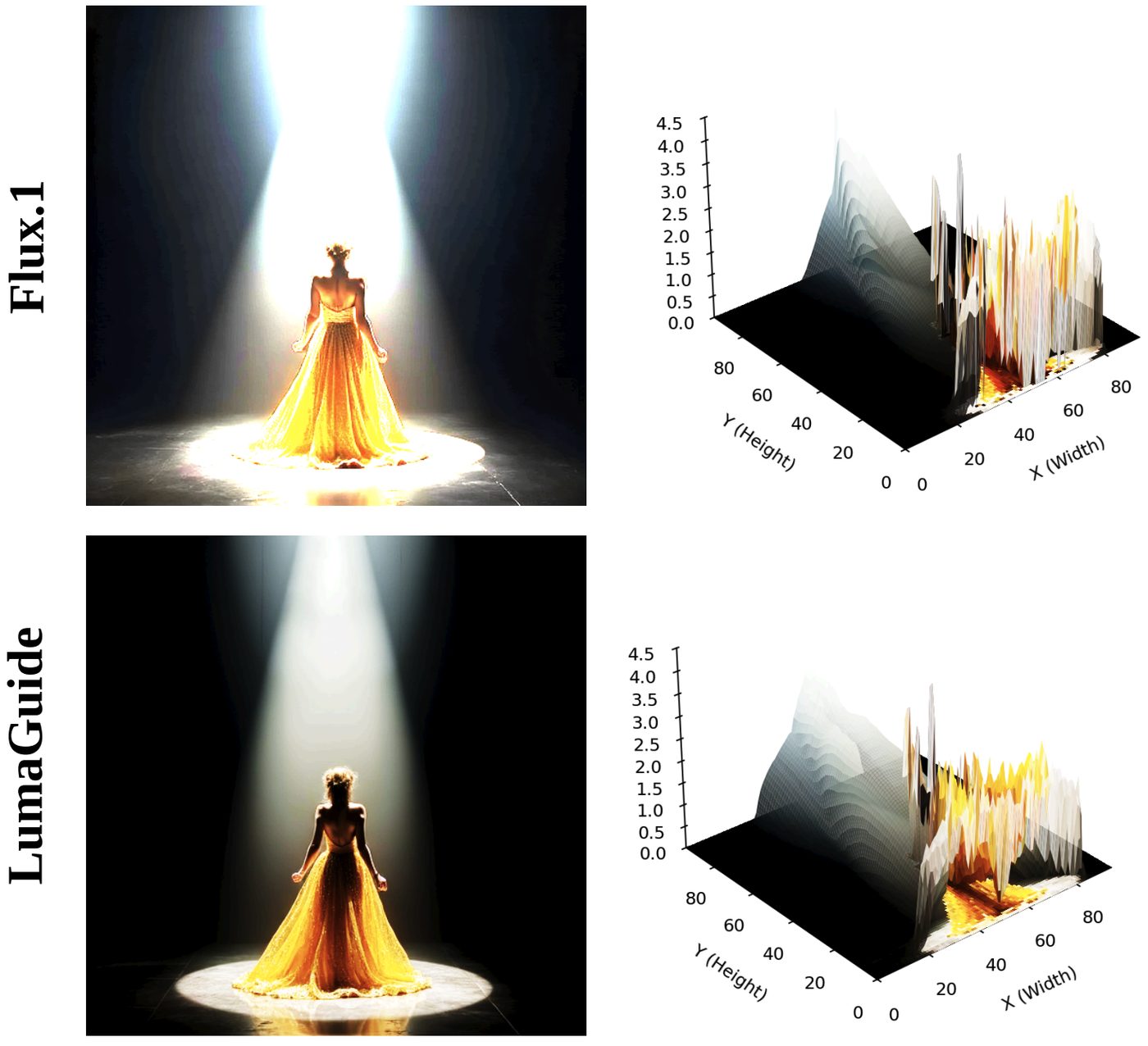
Pretrained diffusion models generate realistic images, but their outputs remain constrained by the statistical biases of their training data, limiting their ability to produce high dynamic range (HDR) content. In this work, we introduce LumaGuide, a training-free framework for distribution shaping in diffusion models. Instead of modifying model parameters, LumaGuide steers the sampling process to match target feature distributions via differentiable energy-based guidance. We instantiate this framework for HDR generation by controlling luminance distributions in perceptually uniform PQ space. Our results show that aligning luminance histograms can induce HDR-consistent behavior, including coherent highlights and preserved shadow detail, while maintaining semantic fidelity. Beyond HDR, LumaGuide enables flexible specification of target distributions through data-driven presets, reference images, or text-driven predictors, and extends naturally to video generation with temporal consistency constraints.
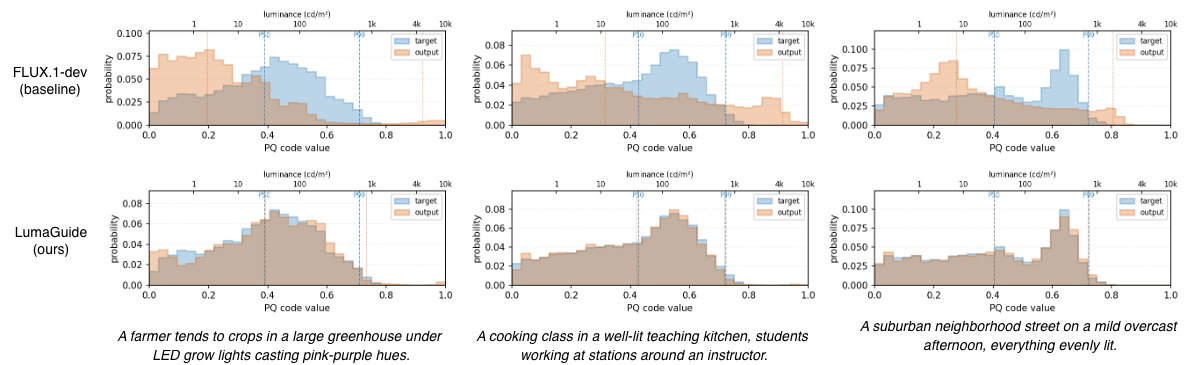
At every denoising step, LumaGuide computes a differentiable soft histogram of the predicted clean image in perceptually uniform PQ space and minimizes a Wasserstein-1 distance to a target histogram. The resulting gradient is back-propagated through the VAE decoder to shape the sampling velocity. Because the histogram is permutation-invariant, the diffusion prior is free to handle semantics and spatial structure — LumaGuide only constrains the global luminance statistics.
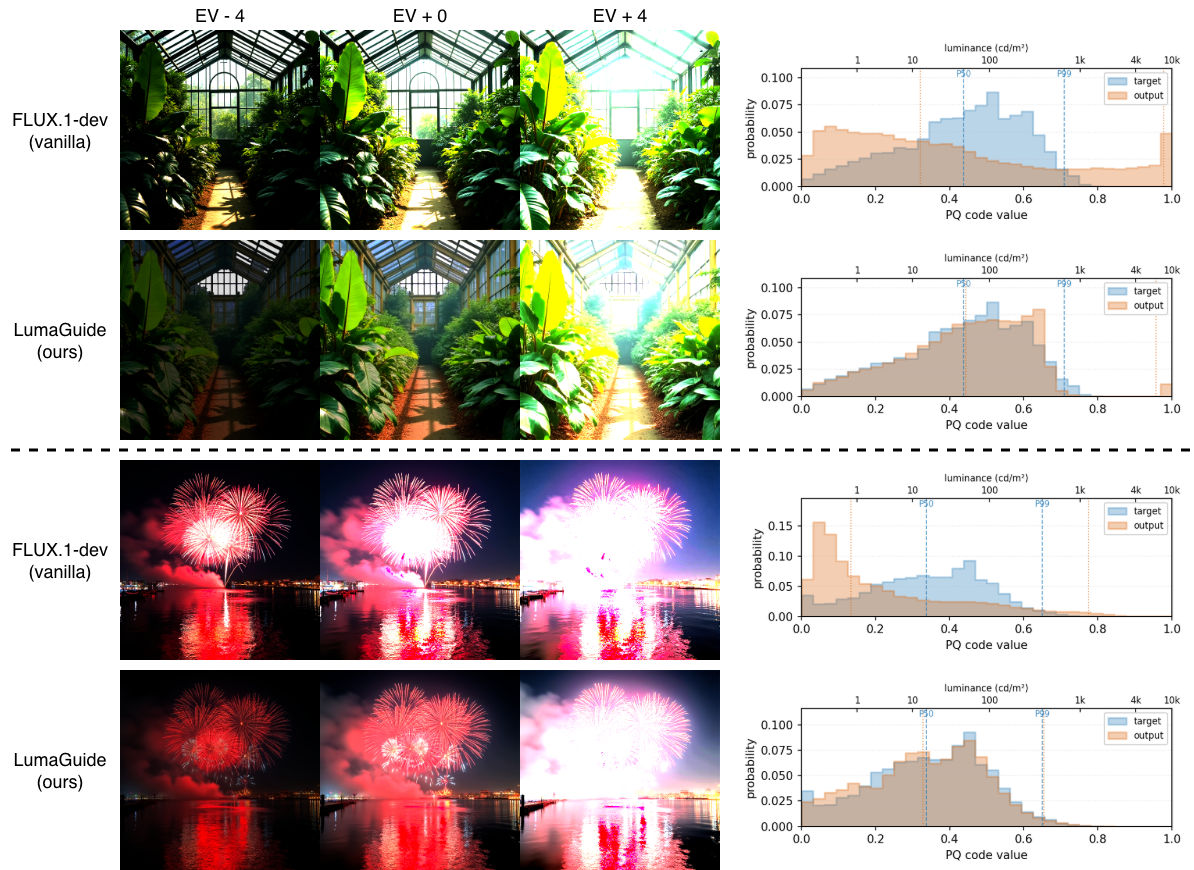
LumaGuide reshapes the generated PQ-luminance histograms toward the target HDR distribution while preserving semantic structure, across Flux.1, SD3, SDXL, and CogVideoX. No fine-tuning is required.
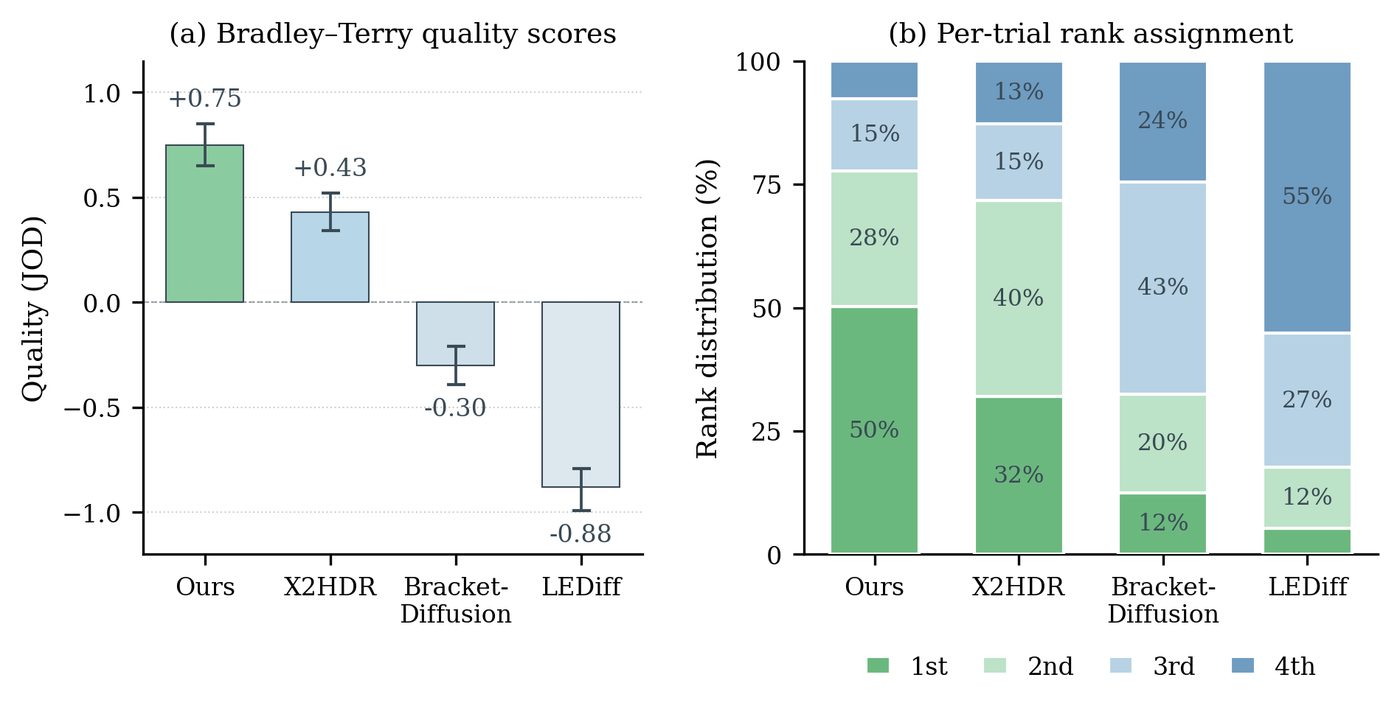
Best value per column is in bold. LumaGuide rows are highlighted. Arrows indicate the direction of better.
Best alignment and largest dynamic range — competitive quality, moderate runtime, and entirely training-free.
| Method | Q-quality ↑ | Q-alignment ↑ | DRstops ↑ | JOD ↑ | Time ↓ |
|---|---|---|---|---|---|
| LEDiff | 0.425 | 0.612 | 4.71 | −0.88 | ~8.6 s |
| BracketDiffusion | 0.448 | 0.648 | 12.25 | −0.30 | ~389 s |
| X2HDR | 0.579 | 0.773 | 11.41 | +0.43 | ~6 s |
| LumaGuide | 0.568 | 0.814 | 14.99 | +0.75 | 7.8 s |
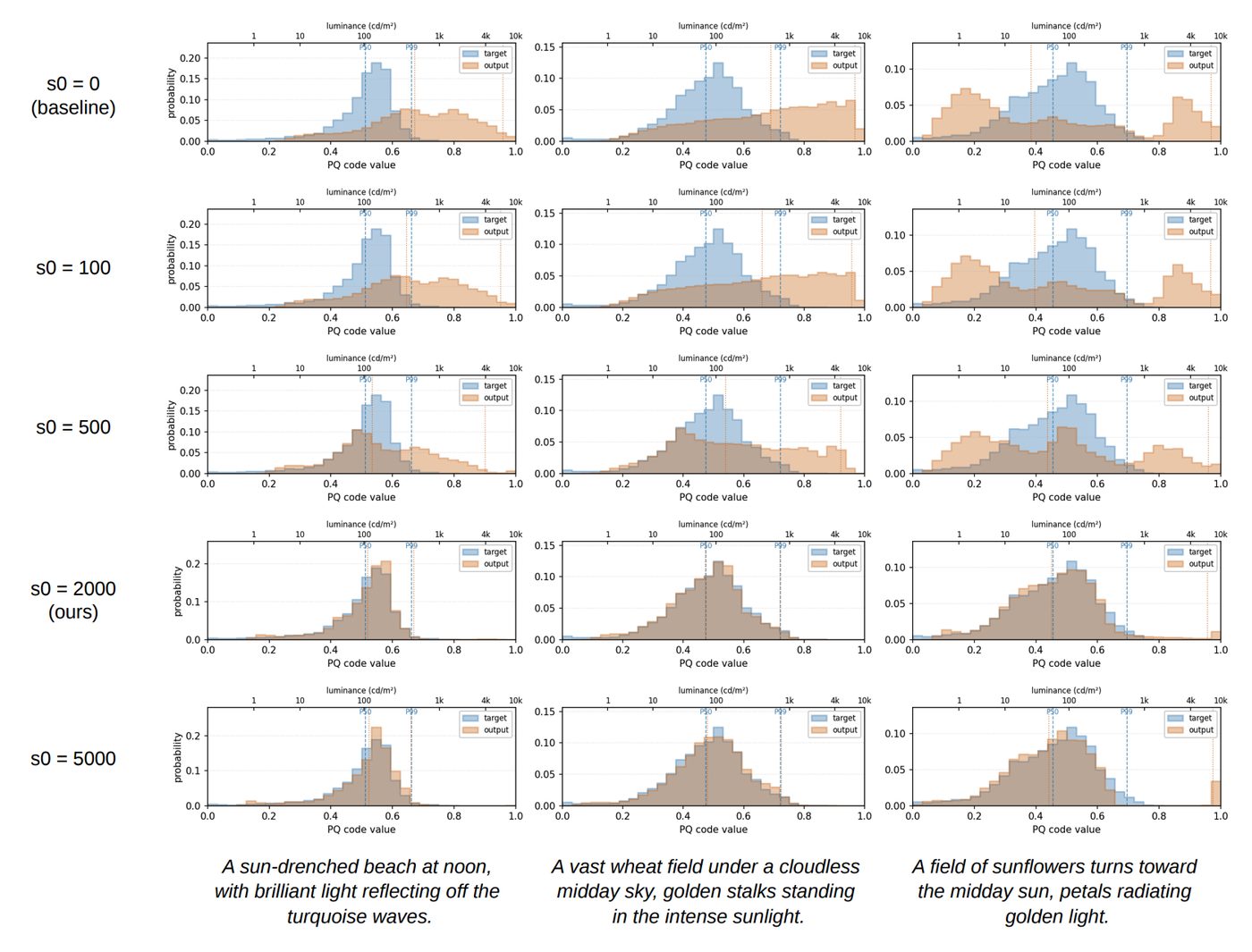
PQ-space guidance with W1 dominates linear-domain and ℓ2/KL variants.
| Domain | Distance | uW1 ↓ | p50dist ↓ | p99dist ↓ | DRstops ↑ |
|---|---|---|---|---|---|
| Linear | W1 | 3.73 | 0.115 | 0.199 | 16.37 |
| Linear | ℓ2 | 3.79 | 0.116 | 0.207 | 16.33 |
| PQ | ℓ2 | 3.40 | 0.100 | 0.206 | 16.18 |
| PQ | KL | 2.06 | 0.065 | 0.143 | 16.51 |
| PQ | W1 | 0.58 | 0.024 | 0.053 | 14.99 |
Drop-in across Flux.1, SD3 and SDXL — no retraining.
| Backbone | Q-quality ↑ | Q-alignment ↑ | DR (stops) ↑ |
|---|---|---|---|
| Flux.1 | 0.568 | 0.814 | 14.99 |
| SD3 | 0.512 | 0.795 | 15.42 |
| SDXL | 0.431 | 0.655 | 15.90 |
Applying the same distribution shaping objective to a pretrained video diffusion model (CogVideoX) yields zero-shot HDR video synthesis. A Temporal Luminance Coherence (TLC) term penalizes highlight flicker across frames while preserving motion and semantics.

@article{chen2026lumaguide,
title = {LumaGuide: Distribution Shaping for Training-Free HDR Generation in Diffusion Models},
author = {Chen, Bowen and Saini, Shreshth and Adsumilli, Balu and Bovik, Alan C.},
journal = {arXiv preprint},
year = {2026}
}