|
I recently completed my PhD at Laboratory of Image and Video Engineering at The University of Texas Austin, advised by Prof. Alan C. Bovik . My research focuses on the Theoretical Foundations of Generative Models (e.g. Flows, Diffusion, and MLLMs) and their applications in Image/Video Generation, efficient sampling, image/video-quality assessment, image/video editing, and inverse problems (eg: ITM). I collaborate with YouTube/ Google Media Algorithms team in my PhD. I was a Student Researcher in the LUMA team at Google Research. Before starting my PhD at UT Austin, I worked as a Research Engineer (AI) at Arkray, Inc. and BioMind AI, Singapore. At both places, I was working on developing novel and scalable AI solutions for medical image analysis. During my undergrad, I was fortunate to be advised by Prof. Mengling Feng (NUS, Singapore), Prof. Aditya Nigam (IIT Mandi), and Prof. Anil K. Tiwari throughout my research. If you want to work with me, please feel free to reach out. I'm happy to advise and collaborate. 📮 saini[dot]2[at]utexas[dot]edu Contact / Google Scholar / LinkedIn / X / GitHub / CV (2026) |

|
|
|
 Student Researcher,
Student Researcher,  Applied Scientist - II Intern,
Applied Scientist - II Intern,  Research Intern,
Research Intern,  Graduate Research Assistant,
Graduate Research Assistant,  Co-Founder, Short-X, Austin
Co-Founder, Short-X, Austin Research Engineer - AI,
Research Engineer - AI,  Research Engineer - AI,
Research Engineer - AI,  Research Assistant,
Research Assistant,  Undergraduate Researcher, Image Processing and Computer Vision Lab, IIT Jodhpur
Undergraduate Researcher, Image Processing and Computer Vision Lab, IIT Jodhpur Research Intern, The Multimedia Analytics, Networks and Systems Lab, IIT Mandi
Research Intern, The Multimedia Analytics, Networks and Systems Lab, IIT Mandi|
|
|
|
|

|
S Saini Open-source release, 2026 Page / Code / Blog Fleetcraft is an open playbook and toolkit for running video generation research on GPU fleets. It packages the skill files, agent guides, Python utilities, spool and fleet scripts, and Slurm templates distilled from real diffusion training and RL projects, with telemetry and monitoring baked in. |
|
|
|
|
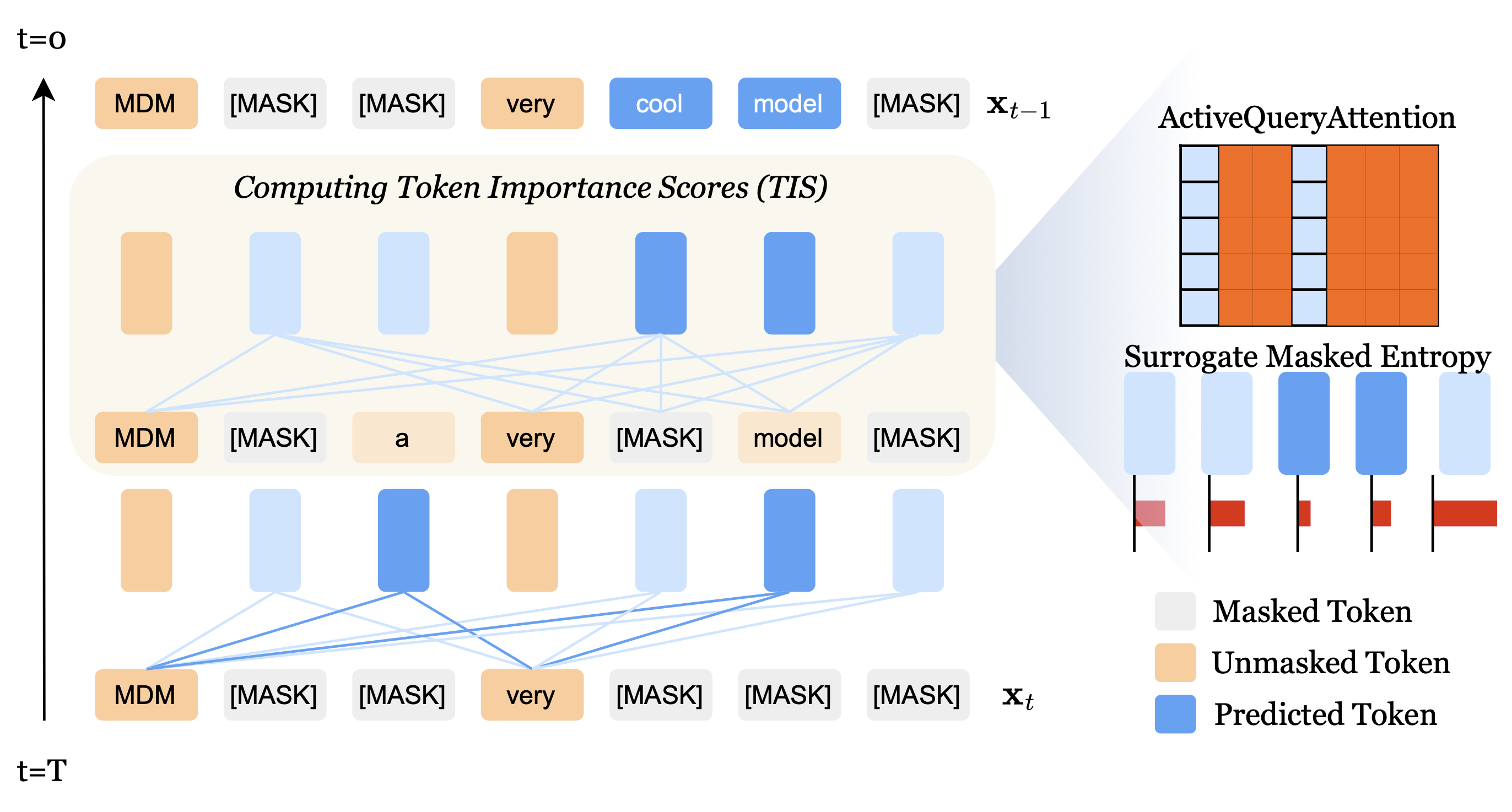
S Saini, A Saha, B Adsumilli, N Birkbeck, Y Wang, AC Bovik. Under Review PDF / ArXiv / Page / Code We introduce TABES, a novel trajectory-aware entropy steering mechanism for masked diffusion models that improves token prediction through adaptive backward sampling guided by information-theoretic principles. |
|
|
|
|
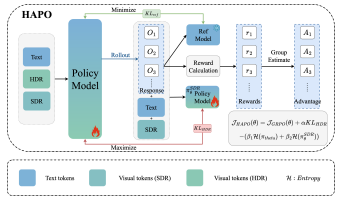
S Saini, B Chen, N Birkbeck, Y Wang, B Adsumilli, AC Bovik. The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026 PDF / ArXiv / Page / Code We present the first large-scale crowdsourced subjective study and a novel RL trained MLLM-based objective QA baseline for HDR-UGC videos, enabling reliable reasoning-based assessment of real-world HDR content. We also propose a novel RL training strategy "HAPO" to learn HDR aware features. |
|
|
|

|
S Saini, N Birkbeck, Y Wang, B Adsumilli, AC Bovik. Under Review 2026 ArXiv / Page / Code / Blog CachedSearch makes best-of-N test-time search in video generation affordable. Candidate rankings survive aggressive training-free caching, so every candidate is explored cheaply and only the winner is re-generated at full compute: 94.7% of best-of-8's quality gain at 63% of its cost, with any cache engine and any verifier. |
|
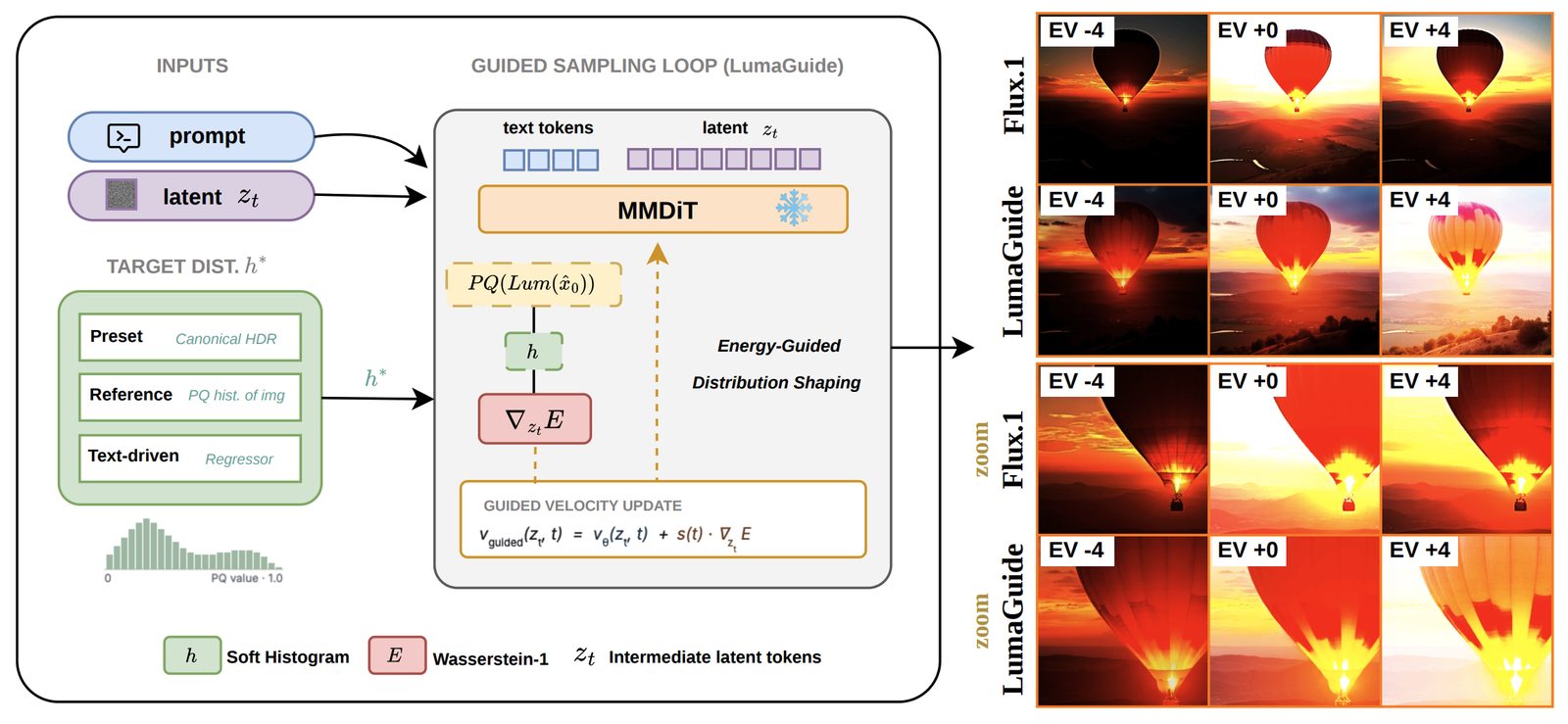
B Chen, S Saini, B Adsumilli, AC Bovik. Under Review - NeurIPS 2026 PDF / ArXiv / Page / Code LumaGuide is a training-free framework for distribution shaping in diffusion models. Instead of modifying model parameters, it steers the sampling process to match target feature distributions via differentiable energy-based guidance, instantiated for HDR generation by controlling luminance distributions in perceptually uniform PQ space. The framework supports data-driven presets, reference-image targets, and text-driven predictors, and extends naturally to video with temporal consistency constraints. |
|
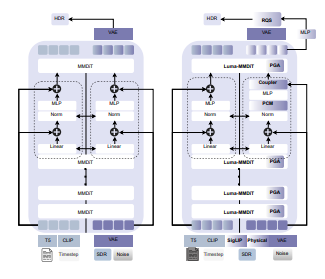
S Saini, H Gedik, N Birkbeck, Y Wang, B Adsumilli, AC Bovik. Under Review PDF / ArXiv / Page / Code LumaFlux introduces physically-guided diffusion transformers (MMDiT) for inverse tone mapping, lifting standard 8-bit content to HDR with physically accurate luminance expansion and color reproduction. We proposed novel architecture changes, scaled UGC SDR-HDR training data & benchmark, and training paradigm. |

|
S Saini, S Gupta, AC Bovik. Thirty-Ninth Conference on Neural Information Processing Systems (NeurIPS 2025) PDF / ArXiv / Page / Code Rectified CFG++ enhances conditional image generation with Rectified Flow models by adaptively correcting the latent trajectory. This method improves visual coherence and alignment with text prompts, outperforming existing samplers in generation quality and efficiency. |
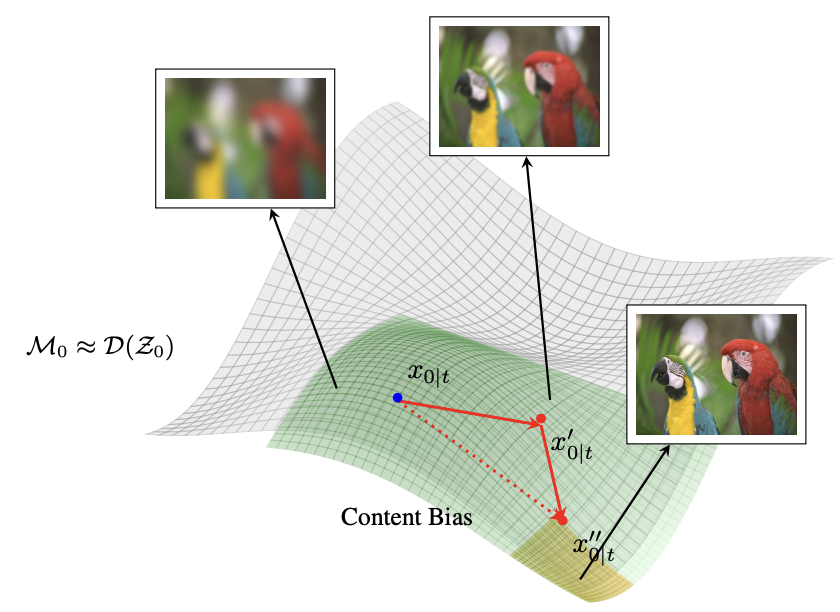
|
S Saini, R Liao, Y Ye, AC Bovik. International Conference on Machine Learning (ICML) 2025 PDF / ArXiv This study investigates the exploitation of diffusion model priors to achieve perceptual consistency in image quality assessment. By leveraging the inherent priors learned by diffusion models, the assessment of image quality is made more aligned with human perception, leading to more accurate and reliable evaluations. |
|
|
|

|
S Saini, B Chen, N Birkbeck, B Adsumilli, AC Bovik IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2026 (Oral) PDF / Page / Code BrightRate is designed for quality assessment in user-generated HDR videos, focusing on capture variability and perceptual fidelity. |
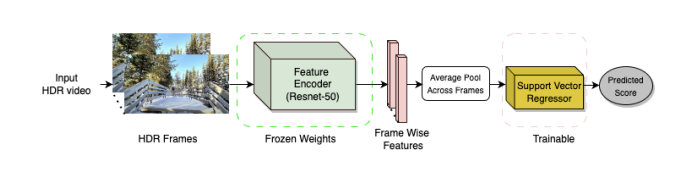
|
S Saini, A Saha, AC Bovik. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2024 PDF / ArXiv / Page / Code Contrastive HDR-VQA introduces a deep contrastive representation learning approach for high dynamic range video quality assessment. By learning robust representations through contrastive learning, the method achieves state-of-the-art performance in predicting the quality of HDR videos. |
|
|
|
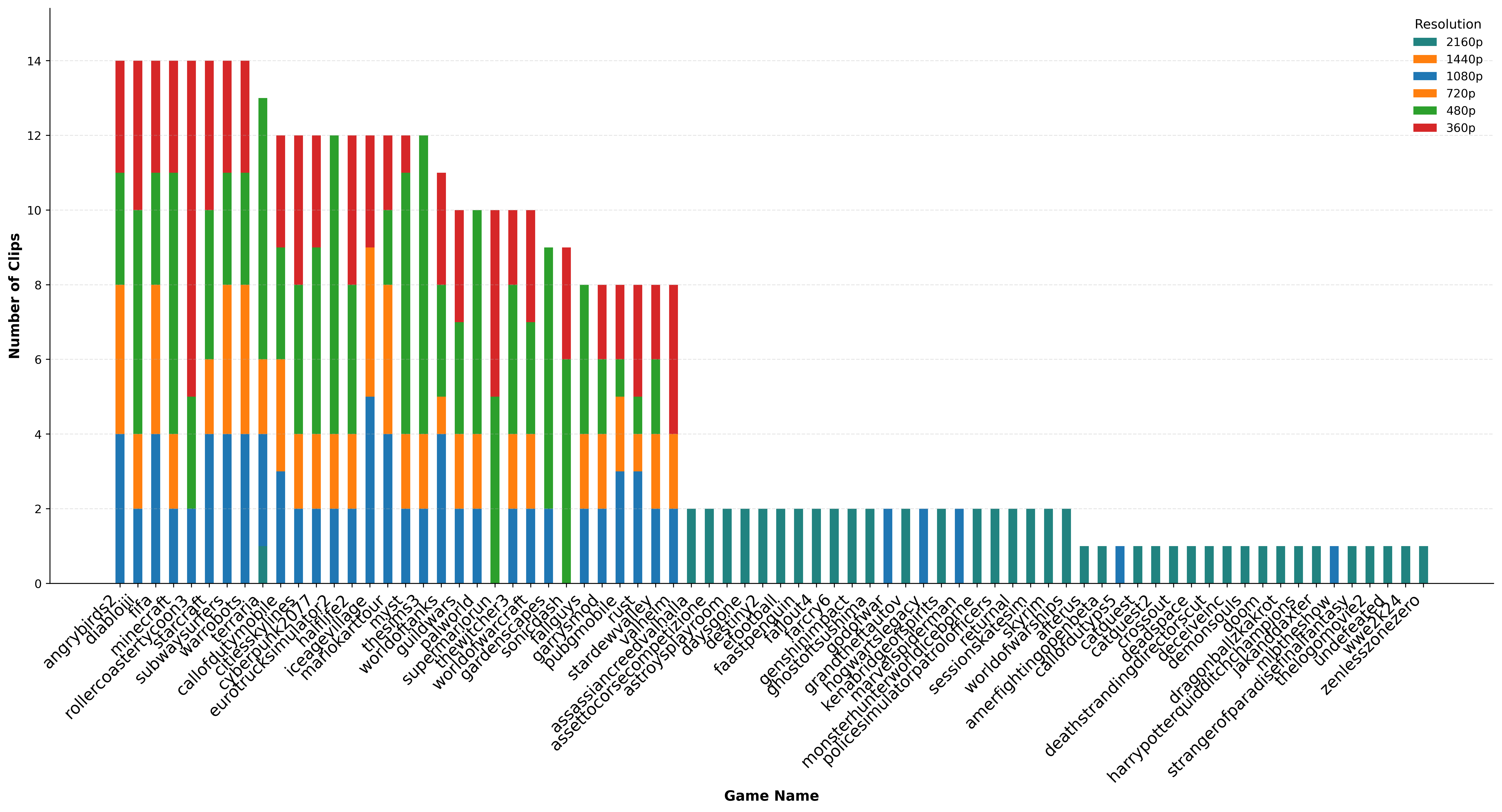
|
R Sureddi, S Saini, A Saha, AC Bovik. IEEE International Conference on Image Processing (ICIP) 2026 PDF / ArXiv / Page / Code GameScope is the largest gaming video quality assessment dataset to date, spanning user-generated and professionally-created content across H.264, H.265, and AV1 codecs. It comprises 4,048 videos with ~37 mean opinion score ratings each and benchmarks leading VQA methods, with a vision–language model baseline outperforming prior approaches. |

|
S Saini, N Birkbeck, B Adsumilli, AC Bovik IEEE International Conference on Image Processing (ICIP) 2025 PDF / ArXiv / Page / Code CHUG is a crowdsourced dataset for HDR video quality, addressing the need for diverse, real-world content. It aids in developing more accurate and robust quality assessment models. |

|
S Saini, P Korus, S Jin. Amazon Prime Air / Perception (Internal) Prime-EditBench is a real-world benchmark designed to evaluate image and video editing with diffusion models, enabling standardized assessment of editing performance. |
|
|
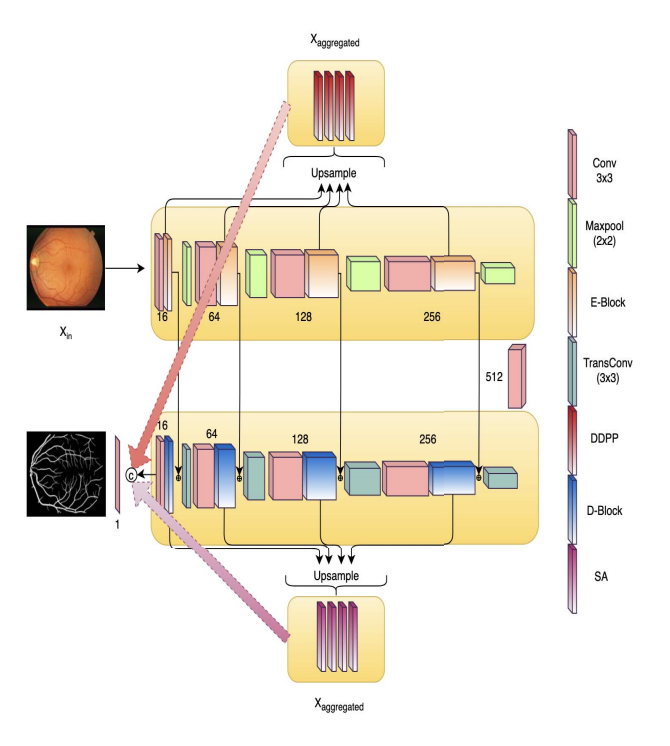
|
S Saini, G Agrawal. IEEE ISBI 2021 & IEEE ICHI 2021 (Oral) IEEE/PDF / ArXiv M2SLAe-Net introduces a multi-scale multi-level attention embedded network for improved retinal vessel segmentation. By integrating attention mechanisms at multiple scales and levels, the network achieves enhanced accuracy and robustness in segmenting retinal vessels, aiding in the diagnosis of various eye diseases. |
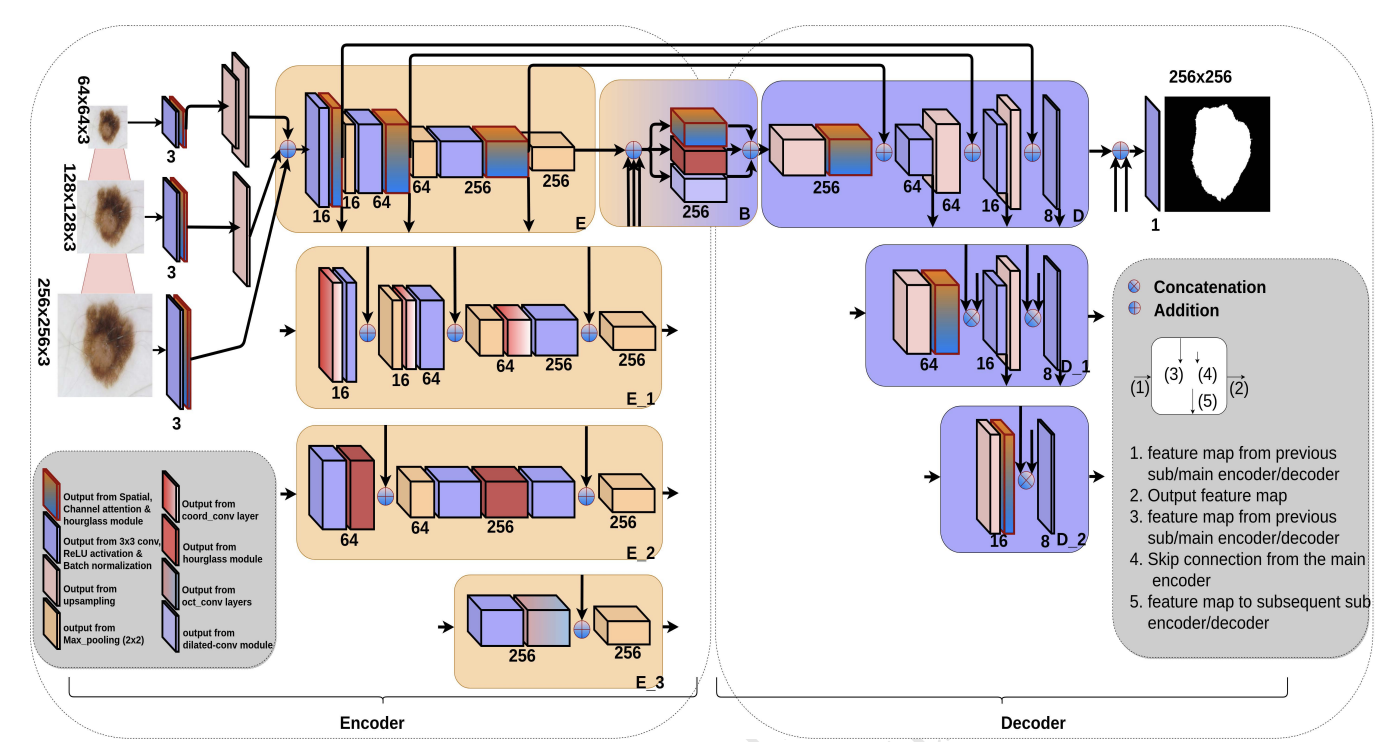
|
S Saini, YS Jeon, M Feng. ACM CHIL 2021 (Oral) B-SegNet introduces a branched SegMentor network for accurate skin lesion segmentation. By employing a branched architecture, the network effectively captures both local and global features of skin lesions, leading to improved segmentation performance and aiding in the diagnosis of skin cancer. |

|
S Saini, D Gupta, AK Tiwari. NCVPRIPG 2019 (Oral) PDF / ArXiv This paper presents a detector and SegMentor network for simultaneous skin lesion localization and segmentation. The network combines detection and segmentation tasks to provide a comprehensive solution for skin lesion analysis, enabling accurate localization and precise segmentation of lesions for improved diagnostic accuracy. |
|
|
|
|
RR Jha, G Jaswal, S Saini, et al. IET Biometrics, 2019 PixISegNet introduces a pixel-level iris segmentation network that utilizes a convolutional encoder-decoder architecture with a stacked hourglass bottleneck. This network achieves precise iris segmentation by effectively capturing both local and global features, making it suitable for various biometric applications. |
|
|

|
S Saini, et al. AI and Deep Learning in Biometric Security, CRC Press, 2020 This book chapter explores the use of encoder-decoder based deep learning techniques for iris segmentation in unconstrained environments. The proposed methods effectively handle challenges such as variations in lighting, occlusion, and off-angle images, making them suitable for real-world biometric applications. |
|
|
|
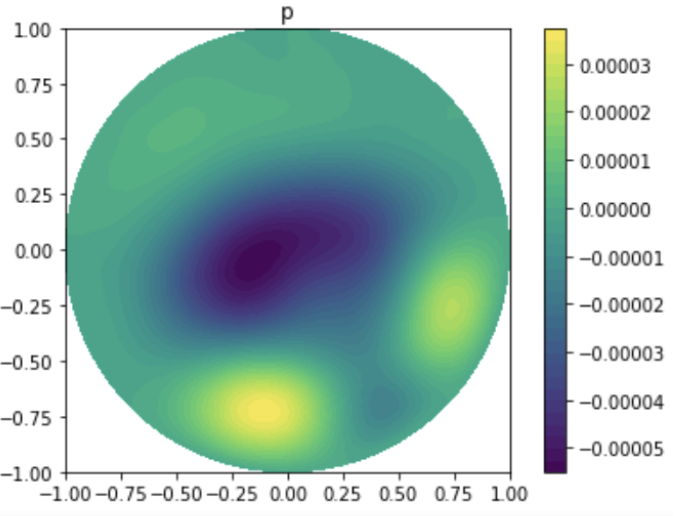
GitHub Repository This repository contains problems and solutions related to general inverse problems, as part of the CSE 393P course. It includes implementations and analyses of various inverse problem-solving techniques. |

|
Shreshth Saini, Yu-Chih Chen, Krishna Srikar Durbha GitHub / PDF Implementation of an efficient SR3 DM for Super Resolution. This project explores the potential of pre-trained diffusion models to enhance the generalization ability and reduce computation costs in image super-resolution tasks. |

|
Shreshth Saini, Krishna Srikar Durbha GitHub / PDF Zero-shot Diffusion Model for Video Animation (Zero-DA) adapts image generation models to video production. This framework tackles the challenge of maintaining temporal uniformity across video frames using hierarchical cross-frame constraints. |
|
Shreshth Saini, Albert Joe, Jiachen Wang, SayedMorteza Malaekeh GitHub / PDF This project aims to mitigate the inherent bias in recidivism score predictions by leveraging machine learning techniques to rectify and minimize biases towards gender and racial/ethnic groups. |
|
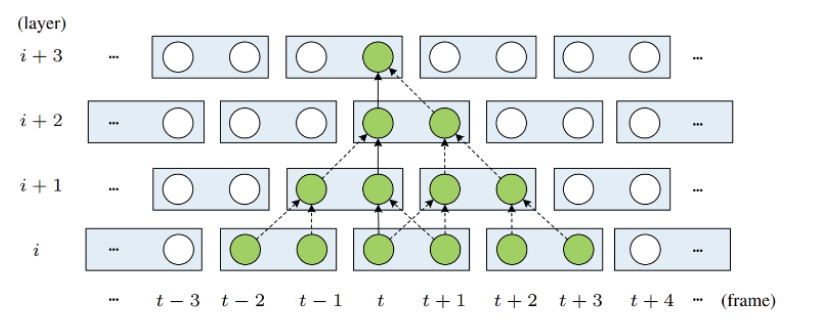
Shreshth Saini, Krishna Srikar Durbha GitHub / PDF This project proposes the use of transformers to learn long-range interactions with mutual self-attention between frames as a surrogate for motion estimation in video frame interpolation. |
|
Reviewer and Program Committee Member
AAAI2027
ICLR2025, 2026
ICML2025, 2026
NeurIPS2025, 2026
CVPR2025, 2026
ICCV/ECCV2025, 2026
WACV2024, 2025, 2026
IEEE TIP2025, 2026
IEEE Trans. on Multimedia2024, 2025, 2026
TMLR2025, 2026
Other Service
Assistant Director, LIVE at UT Austin2025-2026
Volunteer, Internal Workshop on Deep Learning (IWDL), India2018
Established and ran LAMBDA Lab at IITJ2018-2020
Overall Head, Entrepreneurship and Innovation Cell at IITJ2018-2019
Assistant Head, Counselling Services at IITJ2018-2019
|

|