Thesis. Classifier-free guidance (CFG) was designed for stochastic diffusion SDEs, where renoising at each step corrects extrapolation errors. Flow models solve deterministic ODEs — no renoising, no error correction. Rectified-CFG++ fixes this with a geometry-aware predictor-corrector that stays on the data manifold.
Main technical point. The key insight is replacing extrapolation with interpolation: anchor to the conditional flow velocity, then correct with a time-decaying guidance term that vanishes near the data endpoint.
Practical implication. A drop-in replacement for CFG that requires no retraining. Works across Flux, SD3, SD3.5, and Lumina with consistent improvements in text rendering, prompt adherence, and perceptual quality.
1) Why CFG Breaks on Flow Models
Classifier-free guidance1[3] computes a guided velocity by linearly combining the unconditional and conditional predictions:
\[ \hat{v} = (1 - \omega)\, v^u + \omega \, v^c = v^u + \omega\,(v^c - v^u) \]
When \(\omega > 1\), this is extrapolation: we overshoot past the conditional direction. In diffusion SDEs, this works because each step adds noise back to the sample (the stochastic term in the reverse SDE). This renoising acts as a natural error corrector — it pulls the trajectory back toward the data manifold even when guidance pushes it off.
Flow models are different. They define a deterministic ODE from noise \(x_1 \sim \mathcal{N}(0,I)\) to data \(x_0\):
\[ \frac{dx_t}{dt} = v_\theta(x_t, t), \qquad t: 1 \to 0. \]
There is no stochastic correction. Every error in the velocity field accumulates. When CFG extrapolates the velocity, the ODE trajectory drifts off the learned manifold, and there is nothing to bring it back. The result: oversaturated colors, distorted geometry, and garbled text — artifacts that worsen with stronger guidance.
Here is what this looks like in practice on Flux (a state-of-the-art flow model). Without guidance, the model produces a plausible but undersaturated image. Standard CFG introduces color banding, oversaturation, and text artifacts. Rectified-CFG++ preserves the benefits of guidance while staying on-manifold.
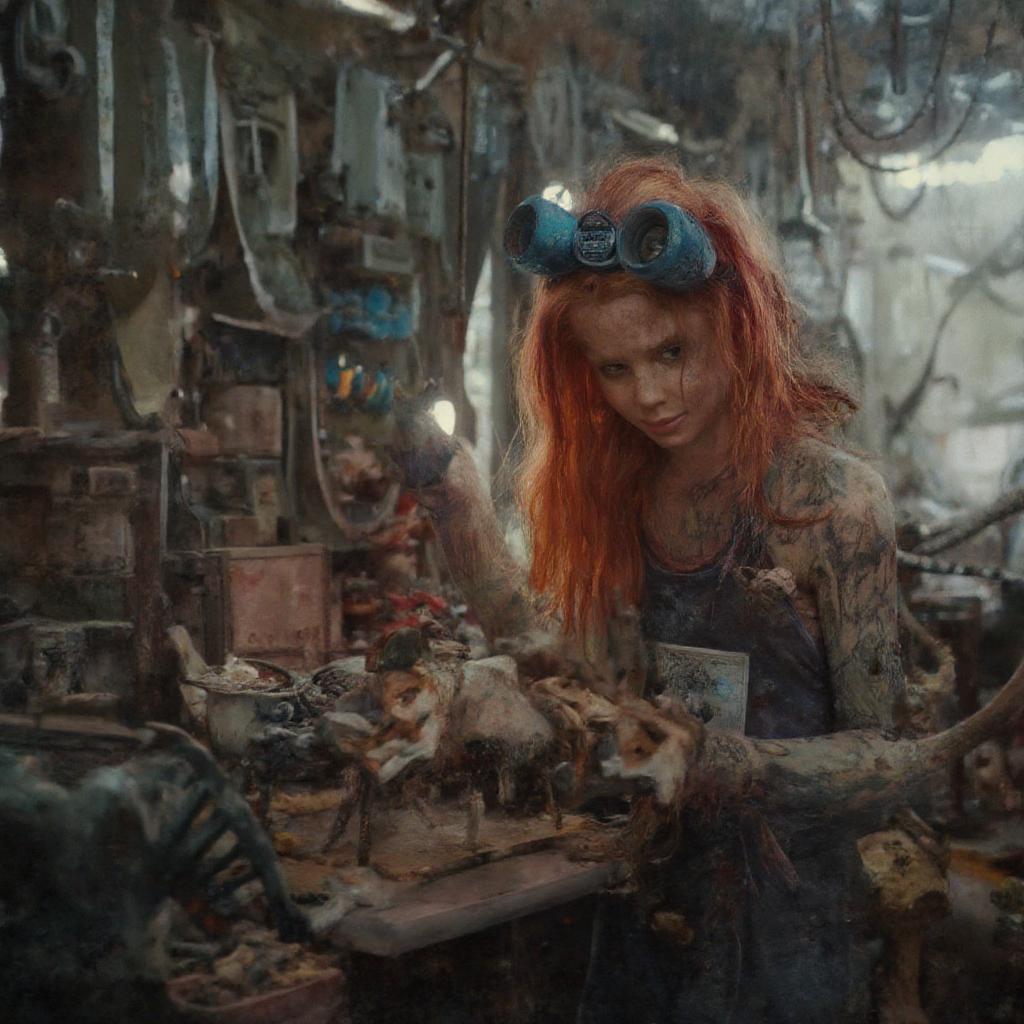
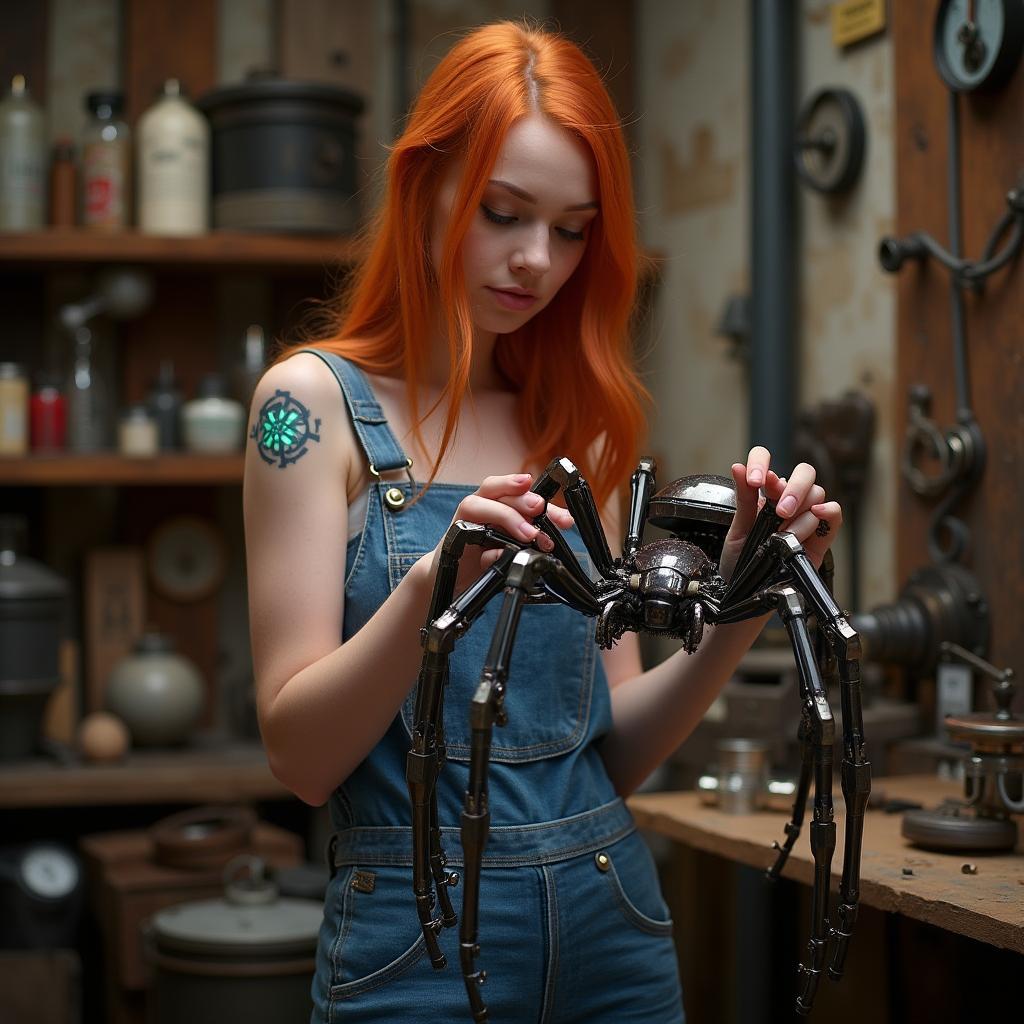

2) The Fix: Predictor-Corrector Guidance
The core idea of Rectified-CFG++2[5] is to replace the naive CFG extrapolation with a two-stage predictor-corrector scheme that anchors to the conditional flow and applies guidance as a bounded perturbation.
The key shift is conceptual: instead of mixing unconditional and conditional velocities at the current point (which creates an extrapolated direction that may point off-manifold), we:
- Follow the conditional flow to a predicted midpoint
- Evaluate the guidance signal (conditional minus unconditional) at that midpoint
- Apply a scheduled correction that decays toward zero near the data endpoint
Algorithm 1: Rectified-CFG++ Sampling Step
- Predictor (half-step along conditional flow):
\(\tilde{x}_{t-\Delta t/2} = x_t + \frac{\Delta t}{2} \cdot v^c_\theta(x_t, t)\) Move halfway using only the conditional velocity. No extrapolation here — this stays on the learned conditional trajectory. - Evaluate at midpoint:
\(v^c_{\text{mid}} = v^c_\theta(\tilde{x}_{t-\Delta t/2},\; t - \Delta t/2), \qquad v^u_{\text{mid}} = v^u_\theta(\tilde{x}_{t-\Delta t/2},\; t - \Delta t/2)\) Compute both conditional and unconditional velocities at the predicted midpoint. - Corrector (anchored guidance):
\(\hat{v} = v^c_\theta(x_t, t) + \alpha(t) \cdot \bigl(v^c_{\text{mid}} - v^u_{\text{mid}}\bigr)\) The anchor is the conditional velocity at the current point. The correction term is the guidance direction evaluated at the midpoint, scaled by \(\alpha(t)\). - ODE update:
\(x_{t-\Delta t} = \text{ODEUpdate}(x_t, \hat{v}, t, \Delta t)\) Standard Euler or midpoint update with the corrected velocity.
The critical difference from standard CFG: the conditional velocity is the anchor, not the extrapolated mixture. Guidance enters only as a perturbation, and the schedule \(\alpha(t)\) controls how much perturbation is allowed at each timestep.
3) The Adaptive Schedule \(\alpha(t)\)
The guidance strength is not a constant. It follows a time-dependent schedule3:
\[ \alpha(t) = \lambda_{\max} \cdot (1 - t)^\gamma \]
where \(\lambda_{\max}\) is the peak guidance strength and \(\gamma \geq 1\) controls the decay rate. The behavior is intuitive:
- At \(t = 1\) (pure noise): \(\alpha(1) = 0\). No guidance at the very start — there is no meaningful conditional signal to amplify yet.
- At intermediate \(t\): \(\alpha(t)\) is large. This is where guidance matters most: the model is committing to global structure (composition, object layout, color palette) and needs the text conditioning signal amplified.
- At \(t \to 0\) (near data): \(\alpha(t) \to 0\). The conditional model alone handles fine details — letter strokes, texture microstructure, edge sharpness. Guidance perturbation would only corrupt these.
4) Why Text Rendering Improves
This is the section that matters most for practitioners4. Text rendering is one of the most visible failure modes of current flow-based generators, and Rectified-CFG++ provides a clean explanation and fix.
The argument is straightforward:
- Text requires pixel-precise strokes in the final denoising steps. The global layout (where the text goes, its approximate size) is determined early. But the exact letterforms — the difference between a legible "STOP" and garbled "STCP" — are resolved in the final steps near \(t = 0\).
- Standard CFG perturbs these strokes. With constant guidance \(\omega > 1\), the extrapolated velocity distorts the fine details that the conditional model had correctly predicted. The model "knows" the right letters but CFG pushes the trajectory off.
- Rectified-CFG++ with \(\alpha(t) \to 0\) near data lets the conditional model finish undisturbed. In the final steps, guidance strength vanishes. The conditional velocity alone determines the fine structure. The result: clean, legible text.
The following comparisons are from SD3. Each pair shows the same prompt and seed; only the guidance method differs. Look at the text regions carefully.
Stop Sign
Prompt: "A realistic photo of a stop sign on a suburban street corner."


Neon Sign
Prompt: "A vibrant neon sign glowing in a dark alley at night."


Carved Text
Prompt: "Ancient carved text on a weathered stone tablet."


Newspaper Headline
Prompt: "A newspaper front page with a bold headline about a scientific breakthrough."


Postage Stamp
Prompt: "A vintage postage stamp with decorative text and border."


The pattern is consistent across all examples: Rectified-CFG++ produces sharper, more legible text. The effect is most dramatic on fine text (stamps, carved inscriptions) where CFG's constant perturbation is most destructive.
5) Theoretical Guarantees
The theoretical analysis5[5] provides two key results that explain why the method works. The proofs are in the paper; here we give the intuition.
Lemma (Midpoint Guidance Consistency)
If the velocity fields \(v^c, v^u\) are \(L\)-Lipschitz and bounded by \(V_{\max}\), then the guidance signal at the predicted midpoint stays close to the guidance signal at the current point:
\[ \bigl\|(v^c_{\text{mid}} - v^u_{\text{mid}}) - (v^c_t - v^u_t)\bigr\| \leq L \cdot V_{\max} \cdot \Delta t \]
In plain terms: evaluating guidance at the predicted midpoint versus the current point introduces an error proportional to step size. For reasonable step counts (20-50), this is small.
Proposition (Trajectory Deviation Bound)
The single-step deviation from the ideal conditional path is bounded by:
\[ \|x_{t-\Delta t}^{\text{guided}} - x_{t-\Delta t}^{\text{cond}}\| \leq \alpha(t) \cdot B \cdot \Delta t \]
where \(B\) depends on the Lipschitz constants and velocity bounds. The key factor is \(\alpha(t)\): because the schedule decays to zero near the data endpoint, the cumulative deviation over the final critical steps is bounded by a quantity that goes to zero.
Geometrically, the guided trajectory stays inside a tube around the ideal conditional path. The tube width is \(\alpha(t) \cdot B \cdot \Delta t\) at time \(t\), which shrinks as \(t \to 0\). Near the data manifold, the tube collapses and the guided path nearly coincides with the conditional path.
6) Results
We evaluate on MS-COCO 10K across four flow-based architectures. The table below reports FID (lower is better), CLIP score (higher is better), PickScore (higher is better), and HPSv2 (higher is better).
MS-COCO 10K: Across Architectures
| Model | Method | FID ↓ | CLIP ↑ | PickScore ↑ | HPSv2 ↑ |
|---|---|---|---|---|---|
| Lumina-Next | CFG | 28.74 | 0.268 | 21.35 | 25.80 |
| Rect-CFG++ | 25.91 | 0.273 | 21.58 | 26.12 | |
| SD3 | CFG | 30.12 | 0.281 | 22.01 | 27.45 |
| Rect-CFG++ | 27.38 | 0.286 | 22.24 | 27.89 | |
| SD3.5 | CFG | 26.85 | 0.289 | 22.18 | 28.01 |
| Rect-CFG++ | 24.12 | 0.293 | 22.41 | 28.37 | |
| Flux | CFG | 24.53 | 0.295 | 22.56 | 28.72 |
| Rect-CFG++ | 22.17 | 0.299 | 22.78 | 29.05 |
Guidance Method Comparison on SD3.5
| Method | FID ↓ | CLIP ↑ | PickScore ↑ | HPSv2 ↑ |
|---|---|---|---|---|
| CFG | 26.85 | 0.289 | 22.18 | 28.01 |
| CFG-Zero* | 25.94 | 0.290 | 22.25 | 28.15 |
| APG | 25.47 | 0.291 | 22.30 | 28.22 |
| Rect-CFG++ | 24.12 | 0.293 | 22.41 | 28.37 |
User Study
In a paired preference study, human evaluators preferred Rectified-CFG++ over standard CFG 72.8% of the time, with particularly strong preference on prompts involving text, fine detail, and complex compositions.
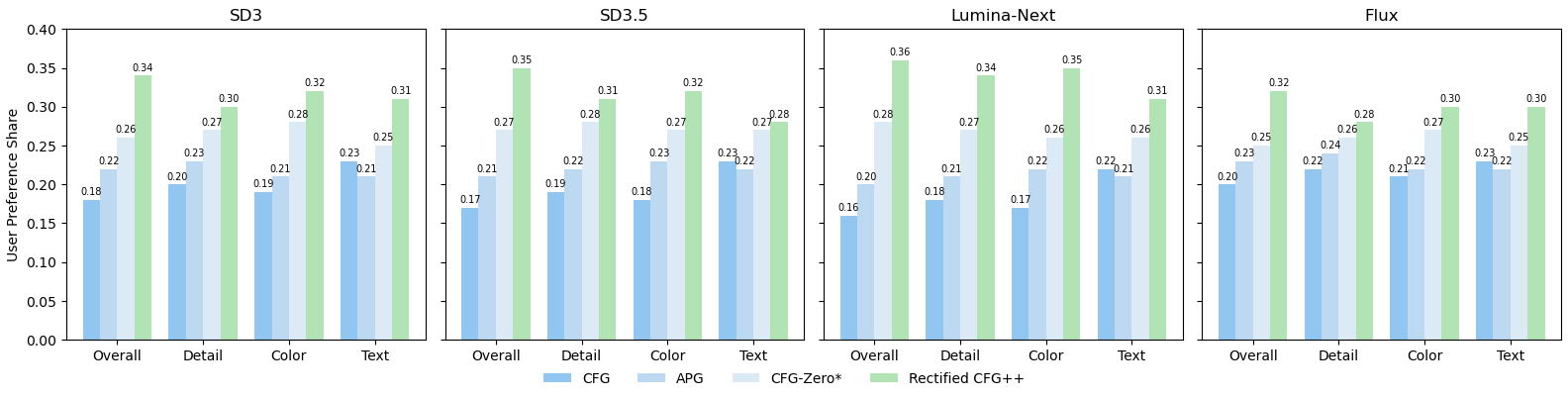

7) Implementation
The implementation is a drop-in replacement for the standard CFG sampling loop. Below is the core logic in Python-style pseudocode.
def rectified_cfgpp_sample(model, prompt, num_steps=28, lambda_max=3.5, gamma=1.5):
"""Rectified-CFG++ sampling loop for flow models."""
# Initialize from noise
x = torch.randn(1, C, H, W)
dt = 1.0 / num_steps
# Timesteps from t=1 (noise) to t=0 (data)
timesteps = torch.linspace(1.0, 0.0, num_steps + 1)
for i in range(num_steps):
t = timesteps[i]
# Adaptive guidance schedule: alpha(t) = lambda_max * (1-t)^gamma
alpha = lambda_max * (1.0 - t) ** gamma
# --- PREDICTOR: half-step along conditional flow ---
v_cond = model(x, t, prompt=prompt)
x_mid = x + (dt / 2) * v_cond
t_mid = t - dt / 2
# --- EVALUATE at midpoint ---
v_cond_mid = model(x_mid, t_mid, prompt=prompt)
v_uncond_mid = model(x_mid, t_mid, prompt=None)
# --- CORRECTOR: anchored guidance ---
guidance = v_cond_mid - v_uncond_mid
v_hat = v_cond + alpha * guidance
# --- ODE UPDATE ---
x = x + dt * v_hat
return xA few implementation notes:
- NFE cost: Each step requires 3 model evaluations (one conditional at current, one conditional at midpoint, one unconditional at midpoint). This is 1.5x the cost of standard CFG (2 evals per step). In practice, you can often reduce the step count by 30-40% at matched quality, so total cost is comparable.
- Hyperparameters: \(\lambda_{\max} \in [2.5, 4.0]\) and \(\gamma \in [1.0, 2.0]\) cover the useful range. Start with \(\lambda_{\max} = 3.5, \gamma = 1.5\) as defaults.
- Compatibility: Works with any flow model that supports conditional and unconditional forward passes. Tested on Flux, SD3, SD3.5, and Lumina-Next without modification.
References
- Liu et al., Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow, 2022.
- Lipman et al., Flow Matching for Generative Modeling, 2022.
- Ho and Salimans, Classifier-Free Diffusion Guidance, 2022.
- Chung et al., CFG++: Manifold-constrained Classifier Free Guidance for Diffusion Models, 2024.
- Saini et al., Rectified-CFG++ for Flow-Based Models, NeurIPS 2025.
- Esser et al., Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (Stable Diffusion 3), 2024.
- Black Forest Labs, Flux.1, 2024.